
Każdy powszechnie używany system IT składa się z wielu warstw oprogramowania. Poczynając od sterowników, przez system operacyjny, kończąc na oprogramowaniu użytkownika. Poszczególne komponenty są tworzone przez różne organizacje. Logiczną konsekwencją jest, że każda z organizacji musi być przez nas obdarzana pewnym kredytem zaufania. Musimy wierzyć nie tylko w to, że organizacje te mają czyste intencje, ale również liczyć na to, że ich oprogramowanie jest wolne od luk bezpieczeństwa. W związku z tym, korzystając z dowolnego oprogramowania okazujemy dwupłaszczyznowe zaufanie.
Wyobraźmy sobie, że chcemy stworzyć średniej wielkości system teleinformatyczny. Jednym z pierwszych wyzwań będzie wybór komponentów i narzędzi. W jaki sposób należy podejść do problemu, aby jednocześnie zachować wysoki poziom bezpieczeństwa i zdrowy rozsądek? Spojrzymy na problem z punktu widzenia osoby, która chce nie tylko zabezpieczyć system, ale także ograniczyć stopień zaufania do zewnętrznych komponentów. Zaczniemy od wyboru systemu operacyjnego, poprzez konteneryzację, a skończymy na zewnętrznych pakietach.
System operacyjny
Osoby posiadające problemy z zaufaniem powinny kierować się ku transparentności. Dlatego pierwszym wyborem będzie dobranie systemu operacyjnego, posiadającego otwarty kod źródłowy. Wobec tego już wiemy, że wybór padnie systemy uniksowe. Jednak ważną kwestią jest to której dystrybucji zamierzamy użyć. Szybkie porównanie ofert o pracę wykazało, że najczęściej używane, uniksowe dystrybucje serwerowe to Debian, Ubuntu oraz CentOS. Dlatego na nich skoncentrujemy się w dalszej części artykułu.
Porównanie dystrybucji
Jednym z kluczowych czynników w zestawieniu bezpieczeństwa wymienionych dystrybucji Linuxa jest polityka aktualizacji w przypadku wykrycia nowych podatności. Zazwyczaj podatności mitygowane są w zbliżonym czasie, jeśli chodzi o Debiana i Ubuntu. Ubuntu jest co prawda forkiem Debiana, ale same aktualizacje pakietów odbywają się niezależnie.
Sprawa wygląda nieco inaczej w przypadku CentOSa, który używa pakietów pochodzących z dystrybucji Red Hat Enterprise Linux (RHEL). Dlatego siłą rzeczy musi być pewne – do 72h opóźnienia, według strony CentOS zazwyczaj aktualizacje są realizowane w ciągu 24h [1] – opóźnienie w aktualizacji pakietów w CentOS względem RHELa. Inną kwestią jest to, że CentOS 8 straci wsparcie z końcem bieżącego roku. Jednak do tego zagadnienia wrócimy w dalszej części artykułu.
W ramach prostego eksperymentu zbadamy szybkość reakcji na podatność oznaczoną CVE-2021-3156. Jest to podatność typu przepełnienie sterty, umożliwiająca eskalację uprawnień w omawianych systemach. Otrzymała ona krytyczność „Wysoki” zgodnie z miarą CVSS v3. Informacje o podatności zostały podane do publicznej wiadomości 26 stycznia 2021. Aktualizacja pakietu dla systemów Debian [2] i CentOS [3] została wydana 20 stycznia, w przypadku Ubuntu [4] aktualizacja była gotowa dzień wcześniej. Jak widać, czas reakcji był bardzo zbliżony. Rozpatrując podobne przypadki można dojść do wniosku, że czas naprawiania podatności niewiele różni się pomiędzy poszczególnymi dystrybucjami. Oczywiście zdarzają się niewielkie odchylenia w wybranych przypadkach, jednak nie ma to widocznego wpływu na całokształt.
W kontekście zaufania do pakietów istotne jest także to, że Debian stosuje „Reproducible Builds”. Oznacza to, że (zgodnie z wiki Debiana): dla każdego pakietu powinna istnieć możliwość odtworzenia go bajt po bajcie. W praktyce oznacza to, że mamy większą pewność, iż na etapie kompilacji kodu źródłowego nie został dodany dodatkowy, potencjalnie niechciany kod. Oczywiście nie jest możliwe, aby każdy użytkownik Debiana próbował reprodukować każdy instalowany pakiet. Ale wystarczy, że jedna osoba wykryje taki incydent i podniesie alarm. Takie podejście developerów Debiana dodatkowo zwiększa zaufanie do tej dystrybucji. W dniu pisania artykułu Ubuntu i CentOS nie posiadały podobnych mechanizmów. Debian wyróżnia się także, jeśli porównamy zespoły odpowiedzialne za omawiane dystrybucje. Debian jest projektem utrzymywanym przez społeczność rozproszoną po całym świecie. Za rozwój pozostałych dwóch odpowiadają w dużym stopniu firmy komercyjne.
Istotną kwestią z punktu widzenia zaufania i prywatności jest kontrowersja jakiej dopuściła się firma Canonical przy tworzeniu starszych wersji Ubuntu Desktop. Mianowicie, Ubuntu w wersji 12.10 domyślnie wysyłało lokalne wyszukiwania do zewnętrznych serwerów, po to aby podzielić się nimi z Amazonem. W ten sposób Amazon mógł lepiej dostosowywać swoje reklamy. Co prawda istniała możliwość wyłączenia tej „funkcjonalności”, ale w pierwszej kolejności nie powinno to być domyślnie włączone. Działania tego typu zostały poddane ostrej krytyce [5]. Począwszy od Ubuntu 16.04 mechanizm jest domyślnie wyłączony. Oczywiście problem dotyczył Ubuntu Desktop, a nie Ubuntu Server, która jest ważniejszym punktem zainteresowania patrząc przez pryzmat przeznaczenia artykułu. Jednak sytuacja rzutuje na zaufanie do firmy Canonical odpowiedzialnej za obie wersje Ubuntu.
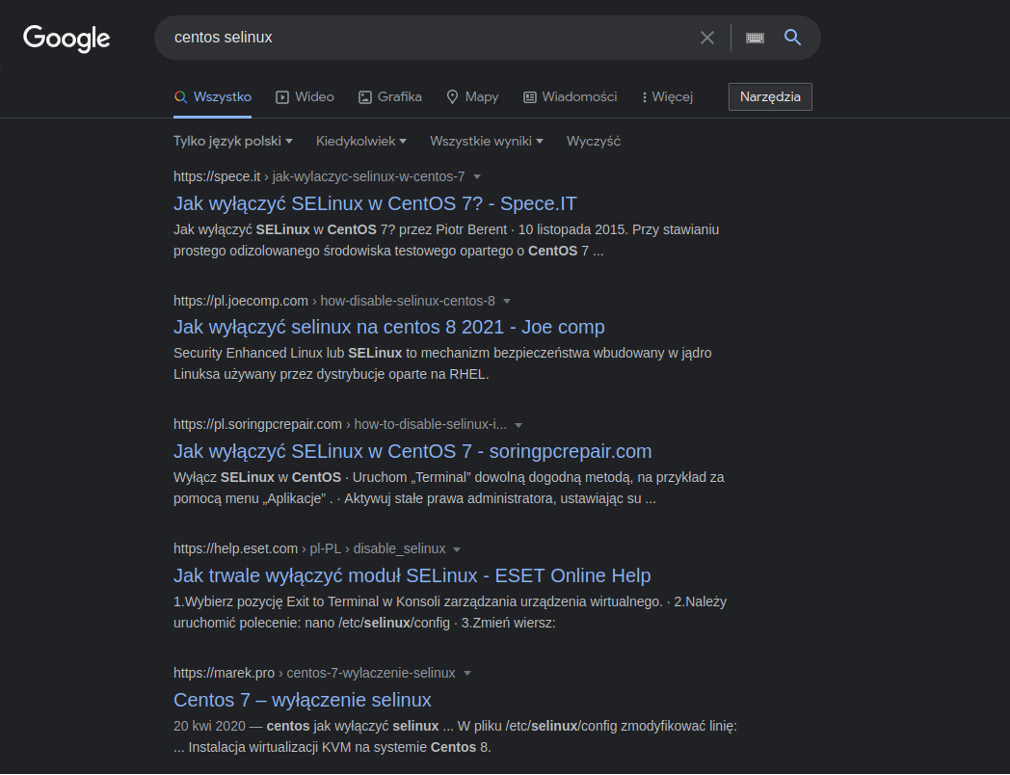
Warto wyróżnić także CentOSa, który jako jedyny domyślnie posiada włączonego SELinuxa. Naturalnie w pozostałych dystrybucjach także można zainstalować to narzędzie, jednak domyślne włączenie jest pozytywnym aspektem biorąc pod uwagę system, który ma służyć jako środowisko produkcyjne. Z drugiej strony, nieco smutne jest to, że 5 najpopularniejszych wyników (w języku polskim, używając najpopularniejszej wyszukiwarki) dla frazy „centos selinux” zwraca informacje o tym jak wyłączyć SELinux:
Na koniec warto wrócić do kwestii poruszonej kilka akapitów temu. Projekt CentOS niedługo przestanie być wspierany, a jego następcą ma zostać CentOS Stream. Dotychczas CentOS był dystrybucją downstream względem RHEL. Gwarantowało to bardzo wysoką stabilność systemu, która jest jednym z najważniejszych czynników w środowiskach produkcyjnych. CentOS Stream zmieni ten stan rzeczy, ponieważ będzie on służył jako „development branch” [6] dla systemu RHEL. Na stronie Red Hata dodatkowo widnieje cytat: „making CentOS Stream a preview of future Red Hat Enterprise Linux releases” [7]. Pociąga to za wątpliwości odnośnie użyteczności systemu w środowiskach wymagających bardzo wysokiej stabilności.
Alternatywą jest dystrybucja Rocky Linux, która doczekała się pierwszej wersji w kwietniu 2021. Osobą odpowiedzialną za utworzenie projektu jest jeden z współtwórców systemu CentOS. Rocky jest przedstawiany jako dystrybucja, który ma zastąpić projekt CentOS. Dla przykładu, szybkie sprawdzenie pokazało, że najnowszy CentOS 8.4 i Rocky Linux 8.4 korzystają z identycznej wersji kernela:

Podsumowując, przedstawione wnioski mogą przychylić się do wyboru konkretnej dystrybucji. W przypadku gdy bierzemy pod uwagę kwestie zaufania do systemu jak i samej organizacji go tworzącej. Natomiast z punktu widzenia zapewniania bezpieczeństwa, systemy reprezentują zbliżony poziom. Wobec tego największe znaczenie dla bezpieczeństwa ma osoba administrująca danym systemem, a nie wybór systemu z omawianej puli.
Hardening systemu
Skoro wybór systemu mamy za sobą, to przyszła pora na hardening. Najbardziej dokładnym rozwiązaniem jest zastosowanie zgodności z benchmarkiem CIS [8]. Dla każdego typu serwera istnieje osobny benchmark, który przedstawia zbiór rygorystycznych wymagań celem zapewnienia wysokiego stopnia bezpieczeństwa systemów produkcyjnych. Wymagania są podzielone na kategorie i w przypadku systemów Linux dotyczą hardeningu:
- Usług – przede wszystkim wyłączanie zbędnych usług
- Sieci – filtrowanie ruchu, segmentacja sieci
- Logów i audytu – konfiguracja auditd, rsyslog lub podobnych, w zależności od systemu
- Kontroli dostępu, uwierzytelnienia i autoryzacji
- I innych, w tym konfiguracji SELinux, odpowiedniego partycjonowania, bezpiecznego bootowania
Manualne zapewnienie zgodności z benchmarkiem CIS byłoby wyjątkowo czasochłonne i żmudne. Dlatego niektóre skanery bezpieczeństwa zapewniają możliwość automatycznego sprawdzenia zaleceń sugerowanych w benchmarku. Do tego celu może zostać użyty Nessus lub rozwiązania Greenbone.
W sytuacji, gdy nie mamy zasobów umożliwiających zapewnienie najwyższego poziomu bezpieczeństwa, możliwe jest także użycie narzędzi, które sprawdzą jedynie najpopularniejsze i łatwe do wykrycia problemy z bezpieczeństwem. Do tego celu może zostać użyty program Lynis [9], który także koncentruje się na hardeningu systemu. Potrafi on wykryć luki bezpieczeństwa nie tylko w konfiguracji systemu, ale także w konfiguracji typowych usług. Istotna jest możliwość sprawdzenia, czy zainstalowane paczki posiadają znane podatności. Natomiast, gdy zależy nam jedynie na sprawdzeniu możliwości eskalacji uprawnień, najbardziej pomocne okażą się narzędzia przeznaczone dla Red Teamingu. Jednymi z najpopularniejszych są LinEnum [10] i LinPEAS.
Prawdopodobnie jest to oczywiste, jednak warto dodać, że samo uruchomienie benchmarku CIS lub narzędzia do audytu zabezpieczeń nic nie da, jeśli nie zastosujemy otrzymanych zaleceń. Tutaj także możemy wdrożyć zalecenia manualnie lub zautomatyzować część procesu. Sporo czasu mogą oszczędzić skrypty Ansible, które automatycznie zastosują zalecenia uniwersalne dla systemów Linux lub zdefiniowane specjalnie dla danej dystrybucji. Skrypty mogą być uruchamiane na kolejnych serwerach produkcyjnych.
Wirtualizacja
Czy coś się zmienia, jeśli chcemy zwirtualizować nasz system operacyjny? Z punktu widzenia bezpieczeństwa jest to dodatkowa warstwa bezpieczeństwa. Jednak należy pamiętać, że nie jest to powodem, aby zaniedbać bezpieczeństwo wirtualizowanego systemu. Przecież staramy się nie uruchamiać podatnych aplikacji webowych, licząc że ochroni nas jedynie WAF. Maszyny wirtualne posiadają własny kernel, a ucieczka z takiego środowiska może skutecznie zniechęcić potencjalnego intruza. Co prawda publikowane są podatności dotyczące poszczególnych hypervisorów, ale mało prawdopodobne jest to, że ktoś w naszym środowisku będzie próbował uruchomić exploit, który jest wart całkiem znaczne kwoty [11] [12].
Dlatego szczególną uwagę należy przyłożyć, aby nasze oprogramowanie wirtualizacyjne było na bieżąco aktualizowane. Natomiast, w przypadku braku możliwości ucieczki ze środowiska wirtualnego, wewnętrzna sieć jest najbardziej obiecującym wektorem ataku. Dlatego należy zwrócić uwagę na możliwości hardeningu sieci hosta oraz dobranie odpowiedniego adaptera sieci w hypervisorze.
Warto także wspomnieć o narzędziu Vagrant, które na przestrzeni lat stało się bardzo popularne. W tym przypadku łatwo zadbać o odpowiednią konfigurację maszyny wirtualnej, która będzie powielana. Najważniejsze jest, aby weryfikować, czy dana maszyna wirtualna (box) jest zaufana. Dlatego sugerowane jest korzystanie ze zbiorów oficjalnych, rekomendowanych boxów. Co ciekawe, twórcy Vagranta podają, że istnieją wyłącznie dwa zbiory oficjalnie rekomendowanych boxów: hashicorp oraz bentoo [13].
Wadą Vagranta jest to, że domyślnie uruchomiona maszyna wirtualna posiada niski stopień bezpieczeństwa konfiguracji. Dlatego od razu po uruchomieniu system powinien zostać odpowiednio shardenowany. Przykładowo, domyślna konfiguracja tworzy użytkownika vagrant posiadającego hasło vagrant. Podobnych „ułatwień” jest więcej, więc trzeba je zidentyfikować i zmodyfikować, aby zwiększyć poziom bezpieczeństwa.
Konteneryzacja
Większość dzisiejszych aplikacji korzysta z kontenerów. Takie rozwiązanie pozwala separować logicznie komponenty systemu, zachowując natywną szybkość działania. Istnieje kilka rozwiązań umożliwiających konteneryzację. Może to być lxd, podman, czy najpopularniejszy Docker. W tym rozdziale skoncentrujemy się na ostatnim, ze względu na wspomnianą popularność.
Kradzież tożsamości kontenerów
Zaczniemy od zagrożenia dotyczącego zbyt dużego zaufania do obrazów. W wielu przypadkach trudno jest potwierdzić wiarygodność danego obrazu. Dla prostego testu, w portalu dockerhub założone zostało nowe konto o nazwie mxlinux [14]. W celu uwiarygodnienia profilu użyty został obrazek dystrybucji MX Linux oraz adres strony internetowej projektu. Celowo nie zostały utworzone żadne kontenery, ponieważ mogłoby to zostać uznane za działanie złośliwe.
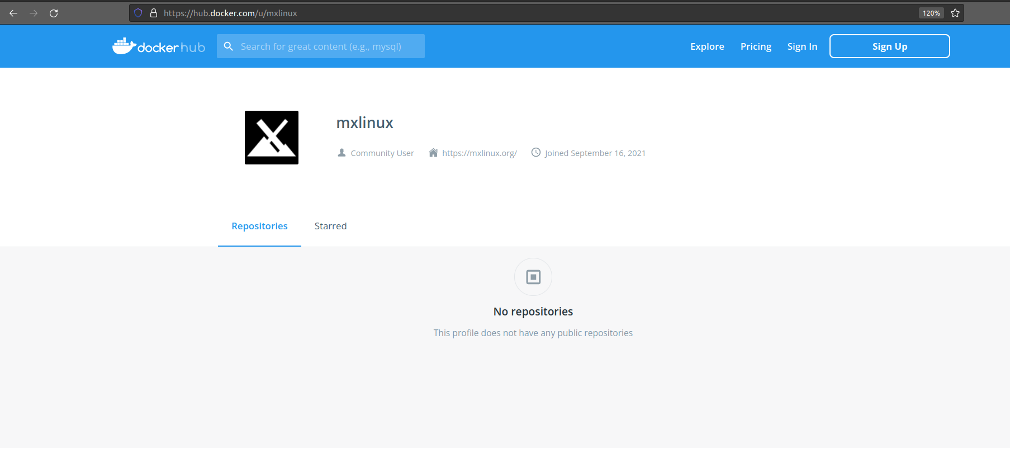
Należy dodać, że MX Linux jest uznawany za dystrybucję wzbudzającą największe zainteresowanie przez stronę DistroWatch [15]. Dlatego atak z użyciem fałszywego profilu Dockera mógłby okazać się wyjątkowo udany.
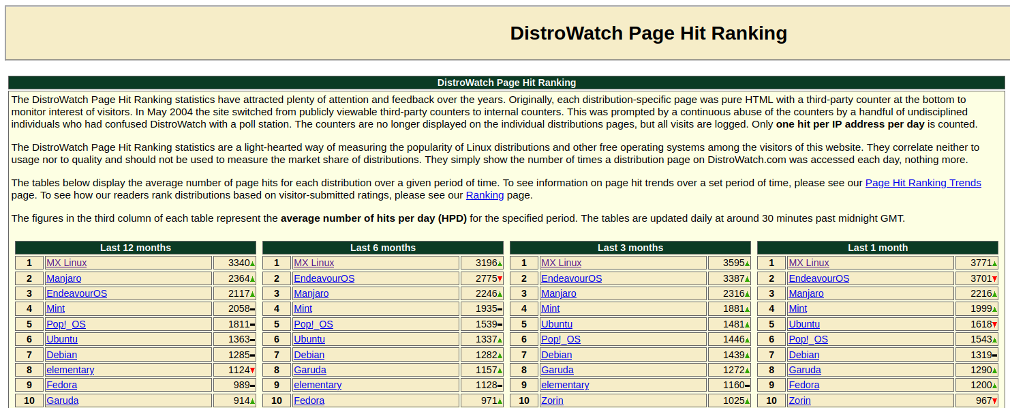
Oczywiście istnieje wiele sposobów kradzieży tożsamości w portalach tego typu. Na potrzeby testów utworzone zostały także inne profile o nazwach „googlealphabet” i „w3af” (nazwa popularnego skanera bezpieczeństwa). Odpowiednio spreparowane profile powinny przyciągać nieświadomych użytkowników. Po założeniu fałszywego konta atakujący może umieścić złośliwy kontener, który umożliwi uzyskanie dostępu do wewnętrznych sieci ofiar.
W jaki sposób przeciwdziałać atakom tego typu? Jednym z mechanizmów są profile zweryfikowane przez Dockera, oznaczone specjalnym znaczkiem „Verified Publisher”. Dodatkową metodą jest sprawdzenie, czy linki do danego profilu Dockera pojawiają się na stronach organizacji, do której ma należeć dane konto. Więcej szczegółowych zaleceń odnośnie zaufanych obrazów można znaleźć w dokumentacji Dockera [16].

Identyczny atak można przeprowadzić z użyciem wspomnianego Vagranta. Jest to nawet łatwiejszy cel ataku ze względu na to, że Vagrant jest mniej popularny niż Docker. Dlatego więcej nazw jest niezarezerwowanych. Na potrzeby testów możliwe było utworzenie profili o nazwie „MIT” lub „RedHat”. Z perspektywy nieświadomego programisty/devopsa nazwy renomowanych uczelni oraz międzynarodowych przedsiębiorstw powinny wzbudzać szczególne zaufanie.
Jak zabezpieczyć Dockera
Zastosowanie dobrych praktyk bezpieczeństwa w przypadku Dockera jest pracochłonnym zadaniem. Istnieje wiele aspektów, które należy przewidzieć. Chyba najbardziej znanym zagrożeniem jest niezabezpieczony socket. Eskalacja uprawnień w tym przypadku jest trywialna:
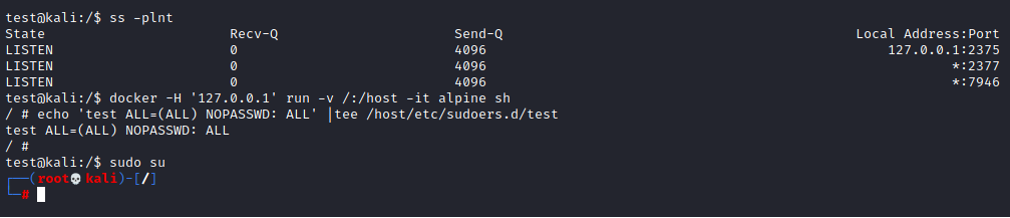
Często jako problem wymieniane jest także to, że kontenery są uruchamiane domyślnie jako użytkownik root. Jest to przypadek specyficzny dla Dockera, ponieważ lxd i podman domyślnie nie używają uprawnień administratora wewnątrz kontenera. Jest to jeden z powodów, dla którego Docker jest rozważany jako mniej bezpieczne narzędzie konteneryzacji.
Osobną kwestią jest konieczność aktualizacji kontenerów oraz oprogramowania używanego przez kontenery. Szczególnie istotne jest to, gdy kontener używa oprogramowania niedostępnego z poziomu menedżera pakietów. Należy dbać, aby takie oprogramowanie było ręcznie aktualizowane.
Kontenery używają tego samego kernela, co host. Dlatego też niezbędna jest separacja zasobów. W tym celu Docker stosuje mechanizm przestrzeni nazw (namespaces) zapewniany przez kernel. Wykorzystanie podatności w kernelu spowoduje eskalację ucieczkę z kontenera [17]. Należy zatem pamiętać, aby na bieżąco aktualizować kernel systemu hosta.
Zbiór zaleceń ([18] [20]) można przedstawić w postaci listy:
- Używaj zaufanych kontenerów Dockera
- Regularnie przebudowuj kontenery w celu eliminowania znanych podatności
- Zabezpiecz socket demona Dockera
- Domyślnie korzystaj z niskouprawnionych kont wewnątrz kontenerów
- Używaj najniższych możliwych uprawnień, dotyczy przede wszystkim:
- linuxowych capabilities
- segmentacji sieci
- ograniczenia dostępnych zasobów z wykorzystaniem cgroups (ochrona przed atakiem DoS)
- ograniczenia uprawnień kontenerów poprzez polityki apparmor lub seccomp
- dostępu do systemu plików hosta z poziomu kontenera
- Ogranicz przechowywanie sekretów wewnątrz kontenera (szczególnie nie należy przechowywać niezabezpieczonych haseł i kluczy w systemie plików)
- Nie używaj flagi –privileged, nie wyłączaj separowanych przestrzeni nazw poprzez użycie flag –net=host, –pid=host, itp.
Dobre praktyki [19]. zalecają również dodanie flagi –security-opt=no-new-privileges, która dezaktywuje bit SUID wewnątrz kontenerów. Działanie widać na prostym przykładzie:
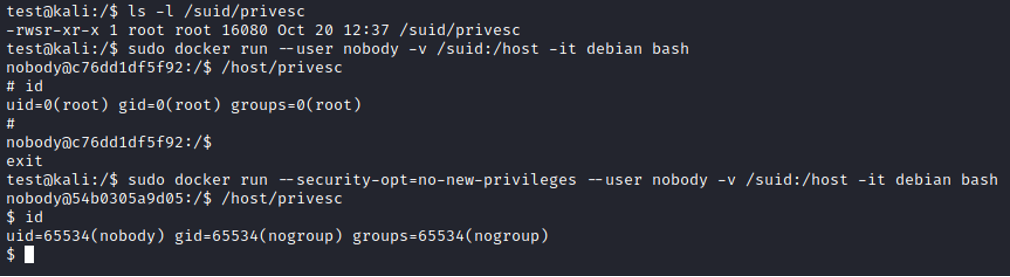
Biorąc pod uwagę ilość sformułowanych zaleceń można pokusić się o stwierdzenie, że z Dockerem jest jak z ciasteczkami w świecie aplikacji web. Oba rozwiązania domyślnie proponują stosunkowo niski poziom bezpieczeństwa, ale odpowiednia konfiguracja pozwala ich używać zachowując spokój sumienia.
Oprogramowanie
Zewnętrzny kod
Wybraliśmy system operacyjny i kontenery. Zaczęliśmy tworzyć swój autorski projekt, jednak wraz z jego rozwojem konieczne stało się użycie paczek stworzonych przez innych użytkowników. W tym momencie także warto przystanąć i zastanowić się, czy nasze przyzwyczajenia są właściwe. Zdecydowanie nie powinniśmy okazywać nieograniczonego zaufania do repozytoriów na GitHubie. Losowa podpowiedź z Internetu brzmi, że powinniśmy sprawdzać każdy kawałek kodu [21]. Aczkolwiek sprawdzanie każdego kawałka oprogramowania linijka po linijce nie jest optymalnym podejściem. Dlatego warto ustalić swój sposób postępowania.
Na problem należy spojrzeć z dwóch stron. Po pierwsze warto zweryfikować, czy sam autor nie posiada złych intencji. Jeśli projekt jest bardzo popularny, to istnieje wyższe prawdopodobieństwo, że ktoś wcześniej przeanalizował kod. Dlatego warto poszukać popularnego substytutu dla mało znanego pakietu. Warto także odszukać inne projekty autora i sprawdzić, czy jest on rozpoznawalny w Internecie. To także może zwiększyć nasze zaufanie do oprogramowania. Oczywiście, najlepszym pomysłem jest analiza kodu, który mamy zamiar używać. Jednak zależnie od projektu, nie zawsze jest to możliwe w określonym limicie czasowym. W tym kontekście użyteczne jest sprawdzenie znanych problemów z repozytorium. Jeśli repozytorium faktycznie zawiera złośliwy kod, to możliwe że ktoś rozpoczął dyskusję na ten temat. W ten sposób mamy nadzieję, że ktoś przed nami zweryfikował rozważany pakiet.
Z pomocą analizy znanych problemów możliwe jest także wykrycie luk bezpieczeństwa w kodzie źródłowym. W ten sposób dochodzimy do drugiego problemu: czy repozytorium posiada znane lub nieznane podatności? Zaadresowanie tego problemu jest nawet trudniejsze. Rozwiązaniem jest monitorowanie bezpieczeństwa pakietu (zależności), w takim samym stopniu jak naszego, autorskiego kodu. Oczywiście ułatwieniem jest, gdy repozytorium należy do znanej organizacji, która przykłada wagę do poprawek bezpieczeństwa. Tutaj po raz kolejny dochodzimy do tematu cyklicznych aktualizacji. Używanie komponentów ze znanymi podatnościami zostało sklasyfikowane na wysokim, szóstym miejscu OWASP Top 10:2021 [22]. Jest to „awans” o trzy miejsca względem OWASP Top 10:2017.
Wśród programistów raczej istnieje świadomość, że nie powinniśmy używać niezaufanych komponentów po stronie serwera. Jednak ciekawe jest to jak często zdarza się, że frontend aplikacji Web używa Javascriptu z zewnętrznych, często niezaufanych serwerów. W tym przypadku monitorowanie złośliwego oprogramowania jest znacznie bardziej wymagające. Przecież nie mamy pewności, że kod Javascript nie zostanie nagle zmodyfikowany. Wstrzyknięcie własnego kodu JavaScript w kontekście sesji użytkownika umożliwi przejęcie sesji, a może nawet doprowadzić do skutecznego ataku na infrastrukturę ofiary. Do przeprowadzenia ataków tego typu istnieją narzędzia [31], które pozwalają na zarządzanie przeglądarkami wielu ofiar i oferują gotowe payloady. Jednym z nich jest możliwość podmiany linków na stronie, w taki sposób, aby atakujący uzyskał persystentną sesję. W połączeniu z keyloggerem rezultaty mogą być bardzo efektowne.
Wstrzykiwanie zewnętrznych kodów JavaScript do naszej strony jest de facto uzależnianiem bezpieczeństwa naszej aplikacji od bezpieczeństwa innych serwerów, udostępniających te skrypty. Uruchamianie zewnętrznych kodów JavaScript rodzi także obawy w związku z prywatnością. W związku z tym dobrą praktyką jest serwowanie skryptów JavaScript wyłącznie z serwera, który jest pod naszą kontrolą. Z perspektywy świadomego użytkownika dobrym posunięciem jest domyślne blokowanie JavaScriptu z użyciem dodatku do przeglądarki internetowej.
Podmiana pakietu
Rozważane dotychczas przypadki dotyczyły sytuacji, w której analizowaliśmy, czy dane oprogramowanie jest godne zaufania. Natomiast w tym podrozdziale zastanowimy się nad sytuacją, w której atakujący podstawił nam złośliwe oprogramowanie. Jeden z bardziej rozpowszechnionych ataków tego typu nosi nazwę typosquatting. Najprościej przedstawiona idea polega na instalacji złośliwego oprogramowania na komputerze ofiary, która niepoprawnie wpisze nazwę pakietu. Dobrym przykładem jest pakiet „cross-env” dostępny z poziomu menedżera pakietów npm. Wpisując nazwę tego pakietu z pamięci łatwo pomylić się i pominąć myślnik. Taką sytuację przewidział atakujący i opublikował swój własny pakiet o nazwie „crossenv” [23]. Stacje robocze, które pobiorą ten pakiet zostaną zainfekowane. Innym przykładem może być popularna biblioteka Pythona o nazwie „urllib3”. Jeżeli pomylimy nazwę i zamiast tego wpiszemy „urlib3” lub „urllib” ponownie staniemy się celem ataku [24]. A przynajmniej tak było kilka lat temu, bo wymienione anomalie zostały zidentyfikowane i wycofane z repozytoriów. Oczywiście wciąż możemy spodziewać się, że podobne przypadki istnieją, ale nie zostały jeszcze wykryte.
Podobnym, niebywale interesującym wektorem ataku jest stosunkowo nowy rodzaj zagrożenia o nazwie „dependency confusion”. Celem ataku są organizacje, które posiadają własne, wewnętrzne repozytoria pakietów. Prywatne repozytoria pakietów mogą posiadać pakiety niedostępne publicznie. Ale co się stanie, jeśli atakujący upubliczni złośliwy pakiet o takiej samej nazwie jak pakiet dostępny tylko z naszego, wewnętrznego repozytorium? W takim przypadku istnieje parę rzeczy, które mogą pójść nie tak. Po pierwsze przy instalacji pakietu możemy zapomnieć dołączyć url naszego repozytorium, więc w konsekwencji domyślnie zostanie pobrany złośliwy pakiet z publicznego repozytorium. Istnieją różne podobne sytuacje, ale ogólnie problem dotyczy niepoprawnej konfiguracji środowiska. Po drugie, niektóre menedżery pakietów mając do wyboru wyższą wersję pakietu z publicznego repozytorium oraz niższą wersję pakietu z naszego repozytorium, mogą wybrać pierwszą opcję. Ponownie zakończy się to kompromitacją naszego systemu. Bardziej szczegółowe opisy „dependency confusion” można znaleźć pod linkiem [25]. Natomiast efektowne skutki wykorzystania podatności są dostępne na stronie [26].
Kontrybucja godna artykułu
Często zdarza się, że oprogramowanie, które chcemy użyć nie jest dostępne z poziomu menedżera pakietów. W takim przypadku stajemy przed decyzją. Poszukać paczki, która będzie gotowa do uruchomienia? Czy poświęcić czas i własnoręcznie skompilować kod źródłowy? W tym przypadku odpowiedź jest prosta. Jeśli mamy wątpliwości odnośnie pochodzenia paczki, zdecydowanie warto poświęcić czas na własną kompilację. W ten sposób wyeliminujemy możliwość dorzucenia złośliwego kodu podczas tworzenia pakietu. Istnieje jednak możliwość, że backdoor intencjonalnie został umieszczony w kodzie źródłowym.
Oprogramowanie open source zazwyczaj posiada wielu kontrybutorów. Mogą oni pochodzić z różnych organizacji i posiadać różne zamiary. W ramach ciekawostki warto rozważyć, co się stanie, jeśli jeden z kontrybutorów okaże się złośliwy. Takie badanie zostało przeprowadzone przez jeden z uniwersytetów w USA. Celem spreparowanego ataku było jądro Linux (!). Ze względu na nieetyczność badania nie zostanie podane, który to był uniwersytet. Nie zostaną także podane linki do artykułu opublikowanego na podstawie badania. Wystarczające będzie poinformowanie, że rzeczony uniwersytet został wykluczony z grona kontrybutorów do kernela.
Kontekst wydarzenia był taki, że pewien uniwersytet chciał sprawdzić jak daleko będą w stanie dojść złośliwe commity. Atak został przeprowadzony przez kilku doktorantów. Ich kod wprowadzał intencjonalne podatności do jądra Linuxa. Zgodnie z listami mailingowymi, spreparowane poprawki osiągnęły gałęzie oznaczone jako „stable” [27] [28]. Nieetyczność badania polegała na tym, że developerzy nie zostali poinformowani, że biorą udział w badaniu. Opisany incydent można porównać do działań RedTeamowych, w których nieświadomy klient nie jest informowany, że został zaatakowany. Działania tego typu nie mogą być aprobowane, dlatego nie dziwi fakt, że uniwersytet został wykluczony z grona kontrybutorów. Mimo to należy mieć na uwadze, że podobny wektor ataku może być wykorzystywany w kompetentny (tj. niewykryty) sposób w publicznie dostępnym oprogramowaniu.
Podsumowanie
Niniejszy artykuł poruszył kwestie zapewniania bezpieczeństwa poszczególnych komponentów systemu, który ma posłużyć jako środowisko produkcyjne dla naszej aplikacji. Zaproponowane zostały najlepsze praktyki bezpieczeństwa, które pierwotnie sformułowane zostały przez branżowe autorytety. Ponadto przeanalizowano sposoby umożliwiające stosowanie zasady ograniczonego zaufania.
W ramach podsumowania należy dodać, że zawsze powinniśmy pamiętać o weryfikacji integralności oprogramowania, które sami pobraliśmy. Do tego celu powinny posłużyć odporne hashe kryptograficzne, typu SHA512. Dotyczy to każdego rodzaju oprogramowania: sterowników, systemu operacyjnego, pakietów, itp. Jako dobry przykład posłuży CentOS, który jest domyślnie pobierany przy użyciu http [30]. Żaden z polskich mirrorów domyślnie nie wymusza szyfrowania. Dlatego modyfikacja ruchu sieciowego poprzez atak Man in The Middle może w prosty sposób zaowocować zupełną kompromitacją naszego systemu.
Wcielając w życie powyższe wnioski można dojść do konkluzji, że zbudowaliśmy całkiem bezpieczny system. Dlatego mogłoby okazać się niefortunne, gdyby wszystkie nasze starania zostały zniweczone przez przysłowiowe wysłanie kodów źródłowych otwartym tekstem przez sieć. Dlatego w ewentualnej kontynuacji artykułu zajmiemy się czynnikiem ludzkim oraz bezpiecznym zarządzaniem sekretami. W międzyczasie warto zapoznać się z garścią dobrych praktyk odnośnie haseł [29].
Linki
[1]https://wiki.centos.org/FAQ/General
[2]https://debian.pkgs.org/10/debian-main-amd64/sudo_1.8.27-1+deb10u3_amd64.deb.html
[3]https://centos.pkgs.org/7/centos-updates-x86_64/sudo-1.8.23-10.el7_9.1.x86_64.rpm.html
[4]https://ubuntu.pkgs.org/20.04/ubuntu-updates-main-arm64/sudo_1.8.31-1ubuntu1.2_arm64.deb.html
[5]https://www.gnu.org/philosophy/ubuntu-spyware.en.html
[6]https://www.centos.org/cl-vs-cs/
[7]https://www.redhat.com/en/topics/linux/what-is-centos-stream
[8]https://www.cisecurity.org/cis-benchmarks/
[9]https://github.com/CISOfy/lynis
[10]https://github.com/rebootuser/LinEnum
[11]https://twitter.com/cbekrar/status/710428332848914432
[12]https://www.eweek.com/security/pwn2own-researchers-reveal-oracle-vmware-apple-zero-day-exploits/
[13]https://www.vagrantup.com/docs/boxes
[14]https://hub.docker.com/u/mxlinux
[15]https://web.archive.org/web/20211015194545/https://distrowatch.com/dwres.php?resource=popularity
[16]https://docs.docker.com/engine/security/trust/
[17]https://www.youtube.com/watch?v=BwUfHJXgYg0
[18]https://docs.docker.com/engine/security/
[19]https://cheatsheetseries.owasp.org/cheatsheets/Docker_Security_Cheat_Sheet.html
[20]https://snyk.io/blog/10-docker-image-security-best-practices/
[21]https://www.quora.com/Can-you-trust-everything-on-GitHub-not-to-be-malicious
[22]https://web.archive.org/web/20211001224020/https://owasp.org/Top10/
[23]https://snyk.io/blog/typosquatting-attacks/
[24]https://snyk.io/vuln/SNYK-PYTHON-URLLIB-40671
[25]https://snyk.io/blog/detect-prevent-dependency-confusion-attacks-npm-supply-chain-security/
[26]https://medium.com/@alex.birsan/dependency-confusion-4a5d60fec610
[27]https://lore.kernel.org/linux-nfs/CADVatmNgU7t-Co84tSS6VW=3NcPu=17qyVyEEtVMVR_g51Ma6Q@mail.gmail.com/
[28]https://lore.kernel.org/linux-nfs/YIAta3cRl8mk%2FRkH@unreal/
[29]https://krebsonsecurity.com/password-dos-and-donts/
[30]http://isoredirect.centos.org/centos/8/isos/x86_64/
[31]https://github.com/beefproject/beef

