
Ars numerandi
Optymalizowanie kodu i wyciąganie z dostępnego sprzętu możliwie jak najwięcej towarzyszyło nam od pierwszych dni informatyki. Wtedy, wynikało w głównej mierze z konieczności – oczekiwania do wyświetlanej grafiki, czy to w grach czy np. w symulacjach, początkowo zawsze przekraczały możliwości dostępnego sprzętu. Pamięć o tych mrocznych czasach powoli zamiera, podania ustne stają się mgliste, ale kiedyś wyświetlenie postaci, przesuwanie tła i zsynchronizowanie 8-bitowej muzyki wymagało napisania wydajnego assemblera, dogłębnej znajomości architektury (Commodore? Atari? ZX Spectrum?) na którą pisało się kod i nierzadko kreatywnego użycia mechanizmów procesora przeznaczonych w zamyśle do czegoś zupełnie innego.
Tęsknotę za tymi czasami widać w niektórych konceptach demosceny – nieco trudnej do uchwycenia subkultury skupionej wokół generowanej komputerowo sztuce – czasem przy naprawdę absurdalnych założeniach. Bo, czy koncept generowania 3 minutowego filmu 3D, z muzyką, za pomocą programu zajmującego 4096 znaków (4x mniej niż ten artykuł) nie wydaje się absurdalny? Szczególnie gdy czytamy o nim na przeglądarce zajmującej ponad 200MB dysku i 8GB (o już 9) RAM?
Dzisiejsza informatyka ma problem z nadwagą, ale nie bez powodu. Kolejne ponakładane na siebie warstwy abstrakcji zmniejszają wydajność, ale pozwalają nam tworzyć i wdrażać rozwiązania szybciej. Tej szybkości zwykle chce od nas biznes, który woli mieć działające rozwiązanie dzisiaj, niż optymalne za miesiąc (lub nigdy). I trudno się kłócić, to zwykle ma sens.
Czasem jednak jest potrzeba by programista wykazał się znajomością tego co leży pod tymi wszystkimi wygodnymi warstwami abstrakcji z którymi pracuje na co dzień. Ta potrzeba to właśnie jeden z powodów dla których bardzo dużą przyjemność sprawiło mi zaangażowanie w tworzenie systemu ochrony przed atakami DDoS “TAMA” – możliwość powrotu do nieco bardziej “pierwotnej” informatyki.
Obrona przed atakami DDoS
Naszym celem nie było generowanie grafiki. Musieliśmy wykryć i odeprzeć (zmitygować) atak, który polega na odmówieniu klientowi usługi – zasadniczo poprzez “wysycenie zasobów” udostępniającego ją serwera. Wysyconymi zasobami zazwyczaj jest łącze, ale może to być również jego pamięć lub CPU.
Wykrywanie polegało na obserwowaniu “metainformacji” o ruchu sieciowym – opisanych za pomocą protokołu Netflow. Informacje te są agregowane i uśrednione, a następnie wykrywamy w nich anomalie, np. przekroczenia skonfigurowanego dla serwera progu. “Meta” dlatego, że netflow to ruch sieciowy opisujący w przybliżeniu inny ruch sieciowy. Nie zawiera on samej treści pakietów i opisuje jedynie jeden pakiet na np. tysiąc przesłanych.
Jednoczesne śledzenie ruchu do parudziesięciu tysięcy adresów, przetwarzanie i odkładanie w bazach informacji o ruchu, nie jest może trywialne, ale nie jest też bardzo wymagające wydajnościowo. Ostatecznie okazało się, że wystarczy nam jedna maszyna fizyczna. Parsowanie pakietów i wstępna agregacja za pomocą C++ i większa część detekcji i obsługi baz napisana w Pythonie. Z tego powodu, detekcja nie jest tematem tego artykułu.
Również nie wszystkie metody mitygacji ataków muszą być trudne w realizacji. Jedną z używanych metod jest odcinanie routingu do atakowanego adresu IP, tzw. “BGP Blackholing”. System wykrywa atak na konkretny docelowy adres IP, który pochodzi zwykle z wielu rozproszonych adresów i… całkowicie odcina do niego ruch. Robi to po to, by ratować pozostałe znajdujące się na danym łączu serwery i usługi. Dla bardzo dużych, kilkudziesięcio gigabitowych ataków, które przeciążają infrastrukturę operatora to może być jedyna faktyczna możliwość ograniczenia wpływu ataku.
Jednak jest to metoda dosyć prymitywna i ograniczając w ten sposób atak realizujemy życzenie atakującego – usługa nie jest dostępna dla klienta.
W pozostałej części artykułu skupię się na wyzwaniach podczas realizacji innego sposobu mitygacji: przekierowania ruchu, zarówno ruchu klientów, którzy chcą skorzystać z usługi, jak i ataku, który próbuje im to uniemożliwić – na jednostki aktywnie filtrujące pakiety sieciowe.
Filtr pakietów
Nie wprowadzaliśmy sztucznych ograniczeń, filtr nie musiał się mieścić w 4096B, ale mieliśmy wystarczająco dużo zmartwień:
- Filtrowanie ruchu musiało być ekonomiczne – PLN/Gbit/s.
- Chcieliśmy, aby rozwiązanie było łatwe do rozszerzania – ataki się zmieniają, my też chcemy. Wprowadzenie zmiany, w duchu devops/agile od konceptu do wdrożenia powinno dać się zrealizować w 1-2 tygodnie.
- Chcieliśmy filtrować ruch możliwie blisko jego źródła – na brzegu naszej sieci, w wielu geograficznie rozproszonych punktach.
Łącza szkieletowe firmy to dziś bardzo często światłowodowe łącza 10GbE, okazjonalnie 40GbE i coraz częściej także 100GbE. W związku z tym chcieliśmy, by pojedynczy serwer z filtrem potrafił obsłużyć 10-40GbE ruchu, bo i tak ze względu na zapewnienie wysokiej dostępności systemu zaplanowaliśmy uruchomienie kilku maszyn.
Przepustowość to jednak nie wszystko. 40GbE to może być prawie 60 milionów pakietów na sekundę (Mpps), jeśli będziemy atakowani małymi, 64-bajtowymi pakietami, lub niecałe 4Mpps jeśli rozmiar ramki sięgnie 1500B. Miara Mpps okazuje się znacznie istotniejsza od przepustowości. Każdej ramce trzeba poświęcić pewien stały czas, przeanalizować nagłówek, zweryfikować odpowiedź mechanizmów filtrowania. Tylko niektóre do podjęcia decyzji będą musiały przejrzeć cały pakiet (np. dopasowania wyrażeniami regularnymi).
Ostatecznie, na podstawie analizy występujących ataków uznaliśmy, że jeden fizyczny filtr powinien obsługiwać co najmniej 10Mpps ruchu. Później okazało się, że to wcale nie było dużo.
Piszemy software!
Ten miks wymagań sprawił, że podjęliśmy decyzję o realizacji filtra czysto programowo, zapewniając by działał na szeroko dostępnych komputerach i “leżących na półkach” kartach sieciowych, tzw. COTS – commercial off-the-shelf. Bez użycia m.in.:
- Dedykowanych układów scalonych (ASIC) przyspieszających konkretne operacje,
- Reprogramowalnych układów (FPGA) zintegrowanych z kartami sieciowymi.
Zamiast tego, użyliśmy dość mocnych maszyn i “nieco lepszych” kart sieciowych, np. dość popularnych kart Intel X710, które umożliwiły podłączenie do serwera czterech łączy o przepustowości 10GbE każde.
Większość monotonnej pracy przy obsłudze ruchu sieciowego, w normalnym systemie operacyjnym, wykona jego jądro (na przykładzie Linuxa):
- Karta sieciowa odbierze pakiet, albo kilka, by nie zawracać systemowi zbyt często głowy (coalesce – jedna z wielu optymalizacji).
- Przerwanie sprawi, że jądro skopiuje dane pakietu do struktury w pamięci (skbuff) i uruchomi analizę poszczególnych warstw protokołów (ethernet, IP, TCP).
- Obsłuży reguły firewalla (iptables, nft) dla pakietu zależnie od jego celu.
- Przyjmie pakiet (to do nas!) i przekaże aplikacji dane poprzez syscall (select, recv), albo w oparciu o tablicę routingu przekaże go po sąsiedzku na inny interfejs sieciowy do odbiorcy lub innego routera.
Te wszystkie kroki sprawiają, że wasza przeglądarka musi się trudzić z obsługą Javascriptu, ale o protokole TCP nie musi wiedzieć za dużo – większość pracy wykonuje za nią system używając do tego interfejsu programistycznego zwanego “Berkeley Sockets”. Jest to prawdopodobnie najstarsze (1983), ciągle szeroko używane i rozpoznawalne API: socket, bind, listen, accept, recv, send, connect.
Niestety, jeśli spróbujecie przepchnąć przez ten pełen stos systemowy 10 Mpps – możecie się zawieść. Przerwania, kopiowanie pamięci, zgodne z RFC parsowanie pakietów, syscalle przekraczające granicę user-kernel space sprawiają, że nowoczesny system komputerowy nie nadąży. Szybko było wiadomo, że realizacja wymagań wydajnościowych wymaga dedykowanego rozwiązania, do którego konstrukcji trzeba będzie się bardziej przyłożyć.
Do stworzenia filtra wybraliśmy bibliotekę DPDK. Dała ona nam mechanizmy pozwalające ominąć system operacyjny przy odbiorze i nadawaniu pakietów i rozmawiać bezpośrednio z kartą sieciową poprzez współdzieloną pamięć RAM – bez niepotrzebnego i kosztownego kopiowania danych. W zamian za to, niezbędne elementy stosu protokołów TCP/IP (Ethernet, VLAN, IPv4, IPv6, TCP, UDP, ARP, ICMP PING, GRE) musieliśmy napisać sami.
Linux ma też wbudowane inne, nowsze i bardziej wydajne API niż Berkeley Sockets (np. PF_RING), ale nie rozwiązują one naszego problemu bardziej kompleksowo niż DPDK.
Komputery są dziś takie szybkie!
Będziemy przetwarzać pakiety szybciej, ale nie rozwiąże to naszych wszystkich problemów. Eksperymentalnie zmierzyliśmy, że przeczytanie pakietu i uruchomienie mechanizmów filtrujących zajmuje nam od 4000 do 11000 cykli procesora w zależności od konfiguracji sposobu mitygacji. Ile cykli mamy dostępnych?
| rozmiar | bity transmitowane | czas tx @40GbE | max PPS | CPU ops/packet | ||||
| 64B | 672 | 0.0168ms | ~ 59mln | ~ 520 | ||||
| 512B | 4256 | 0.1064ms | ~ 9.3mln | ~ 3300 | ||||
| 1500B | 12160 | 0.304ms | ~ 3.2mln | ~ 9400 |
(bity transmitowane uwzględniają inter-frame-gap i preambułę.)
Na łączu 40GbE nowy pakiet o rozmiarze 64B może pojawiać się co około 520 instrukcji procesora, 1500B – co 9400. To mniej niż 11000, które potrzebujemy! Czy procesory są za wolne?
Prędkość z jaką rdzeń procesora może przetwarzać dane nie wzrosła wystarczająco by nadążyć za wzrostem przesyłanych przez nas informacji i przepustowości łączy. Przyrost prędkości w ostatnich latach zwolnił – dobrnęliśmy do procesu litograficznego 5-14nm i zbliżyliśmy się się do twardych fizycznych ograniczeń krzemu. Na szczęście nauczyliśmy się też zwiększać liczbę rdzeni procesora – więc nie wszystko stracone. Żeby osiągnąć cel, jesteśmy zmuszeni do napisania programu równoległego, który będzie się jednocześnie wykonywał na wielu rdzeniach.
Niemniej, zrzucenie całej winy na procesor byłoby znacznym uproszczeniem. Od wielu lat prędkość dostępu do pamięci RAM rośnie wolniej od prędkości procesorów, dostępnej liczby rdzeni procesora i od samego rozmiaru pamięci. Zjawisko to nazywane jest “memory gap” lub “memory wall”. Powszechny w użyciu standard pamięci DDR4 pochodzi z 2014 roku (DDR5 został ogłoszony w lipcu 2020).
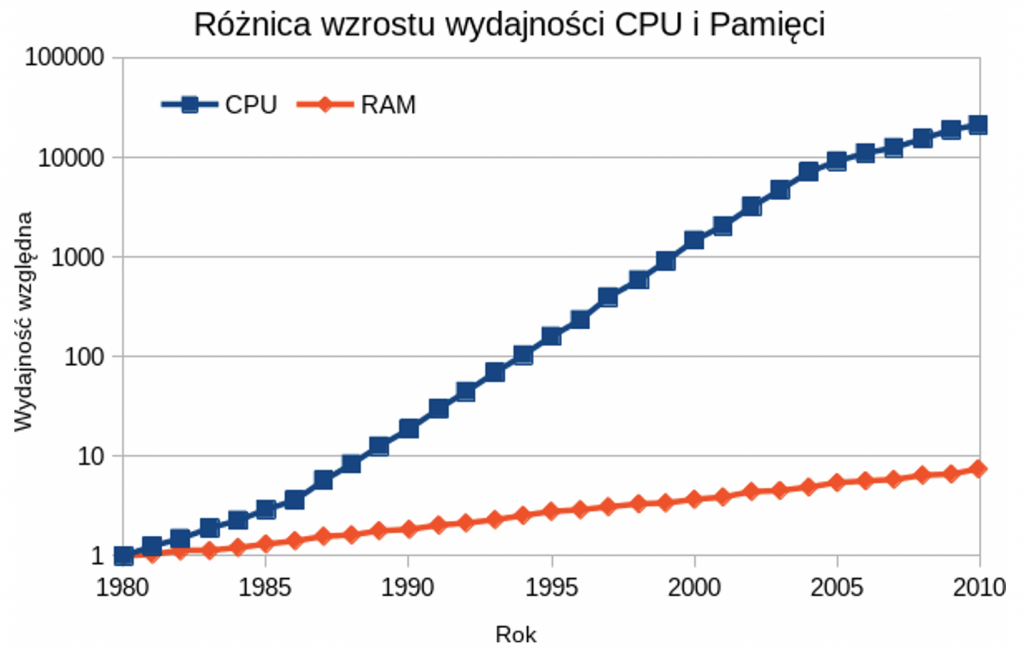
W praktyce procesor bardzo często chciałby pracować, ale nie może, bo czeka na dane. Istnieje cały szereg działań, które mają ten efekt zminimalizować:
- Pamięć cache – każdy rdzeń i procesor mają odrobinę pamięci podręcznej, która jest umieszczona fizycznie bliżej, jest szybsza (i droższa) od pamięci RAM. Jej efektywne użycie jest kluczem do wydajności.
- Kompilatory optymalizujące – mogą zmieniać kolejność wykonywanych operacji programu tak, by pobranie danej z pamięci występowało długo zanim ta informacja faktycznie będzie potrzebna do obliczeń – dzięki temu pamięć zdąży ją dostarczyć do cache’u.
- Głęboki pipeline (potokowość) w procesorach – kiedy jedna instrukcja jest wykonywana przez rdzeń, inna jest pobierana, jeszcze inna dekodowana, tak by optymalnie pracować z wolniejszą pamięcią.
- Instrukcje mogą być nawet wykonywane do przodu – zanim dostaniemy dane do poprzedniej instrukcji, już pracujemy nad kolejną. Przy rozgałęzieniach wykonania (branch, np. warunek “if”), procesor będzie zgadywał w którą stronę warto pójść. Jeśli się pomyli (branch misprediction) może okazać się, że wykonaliśmy trochę niepotrzebnej pracy (10-20 instrukcji), którą trzeba odrzucić i zacząć wykonywać inną. Błędy w tych mechanizmach były przyczyną ataków Meltdown i Spectre.
- Hyperthreading – gdy jeden potok czeka na informacje, drugi może wykonywać instrukcje – dzięki czemu jeden faktyczny rdzeń procesora może wykonywać pracę dwóch.
- Architektury NUMA – jeśli wiele procesorów współdzieli pamięć, memory gap pogłębia się. Można podzielić pamięć na procesory tak, że każdy dysponuje “swoją” pamięcią, a poza tym ma dostęp do “obcej”, do której dostęp jest nieco wolniejszy, ale możliwy. Dobra optymalizacja użycia pamięci na takiej architekturze może znacząco podnieść wydajność, ale jej programowanie jest trudniejsze.
Tematyka jest na tyle złożona, że jeśli kiedyś programista optymalizujący program miał większą szansę w detalach zrozumieć architekturę, na którą tworzył kod (Z80, 6502, …), tak teraz jest to praktycznie niemożliwe. O wiele bardziej opieramy się na empirycznym mierzeniu wydajności fragmentów kodu i eksperymentalnych poprawkach niż kiedyś.
Sprzęt bardzo stara się udawać, że pod spodem nic się dziwnego nie dzieje, a komputer działa tak samo jak w latach 80. Przykładowo do tej samej pamięci RAM może jednocześnie zapisywać i czytać wiele różnych rdzeni procesora, każdy ze swoją pamięcią podręczną. Pomimo to, procesor x86 lub x86_64 zapewnia w niewidoczny dla programisty sposób spójność pamięci podręcznej (cache coherence) – po wykonanym zapisie, wszystkie procesory odczytują nową zapisaną wartość, a nie starą, z pamięci podręcznych.
Zachowanie pamięci zostało dla programisty C++ zdefiniowane dosyć niedawno – standardem C++11. Powstał wtedy model pamięci i narzędzia, które pozwalają wydajnie korzystać z własności sprzętu. Przykładowo wprowadzono zestaw operacji atomicznych na zmiennych (np. test-and-set, compare-and-swap), które twórcy bibliotek języka użyją do zbudowania bardziej złożonych mechanizmów synchronizacji jak semafory i mutexy.
Wymienione mechanizmy sprawiają, że pisanie równoległych programów jest możliwe – ale niekoniecznie łatwe. Procesor może udawać, że wszystko jest jak było, nie ma potoków, problemów z dostępem do pamięci itp. Jeśli programista nie zrozumie, jak pod maską działa to, co robi, taki kod może działać – ale będzie działać wolniej.
Jak pisać kod by osiągnąć wysoką przepustowość?
Co więc zrobiliśmy, aby nasz program, działając w obrębie dostępnych mechanizmów, osiągnął założone 10Mpps?
- Uruchamiamy wiele wątków, przypiętych do różnych rdzeni procesora, tak by każdy rdzeń obsługiwał równolegle część ruchu sieciowego.
- Korzystając ze sprzętowych mechanizmów karty sieciowej, za pomocą biblioteki DPDK, podzielimy ruch sieciowy pomiędzy aktywne rdzenie w taki sposób, by jedno połączenie TCP lub UDP mieściło się na tym samym rdzeniu, np. używając funkcji skrótu na adresach IP: hash(src ip + dst ip) % liczba_rdzeni. Tutaj trochę oszukujemy wspierając się sprzętem, ale jest to funkcja wystarczająco popularna przy szybkich kartach sieciowych, aby z niej skorzystać.
- Każdy z wątków napisaliśmy tak, by nigdy nie wchodził w drogę innym – nie czekał na nie, ani one nie czekały na niego. To oznacza zakaz użycia popularnych, wysokopoziomowych, mechanizmów typu lock/mutex do synchronizacji danych. Inaczej nie uzyskamy liniowego przyrostu wydajności wraz ze wzrostem liczby wątków.
- Skoro nie możemy synchronizować wątków… to nie możemy swobodnie dynamicznie alokować pamięci, a to ogranicza wybór używanych przez nas struktur danych – np. nie można użyć std::set do przechowywania informacji czy już dany adres widzieliśmy.
- Każdy wątek będzie miał dostęp tylko-do-odczytu do części pamięci z konfiguracją systemu, listami adresów IP, itp. Wspólne dane pozwolą efektywnie skorzystać z pamięci podręcznej L3.
- Każdy wątek dostaje również trochę swojej pamięci z możliwością zapisu – do agregacji zdarzeń, statystyk, stanu filtrów. Pamięć alokujemy statycznie przed uruchomieniem filtrowania.
- Mechanizmy w obrębie pojedynczego wątku napisaliśmy optymalizując dostęp do pamięci RAM i unikając rozgałęzień.
- Równoległe wątki trzeba koordynować: przygotować konfigurację mitygacji, zebrać statystyki pracy i skoordynować się z resztą systemu TAMA.
Ostatecznie, stosując DPDK, C++17, struktury danych lock-less i używając np. 12 rdzeniowego procesora taktowanego 3Ghz z pełnym włączonym zestawem filtrów (w tym filtr Regexp – https://www.hyperscan.io) jesteśmy w stanie obsłużyć 25 MPPS na jednej maszynie fizycznej. Stawiając kilka filtrów tego typu w sieci i koordynując ich pracę poprzez scentralizowaną bazę REDIS możemy świadczyć usługę mitygacji ataków, ponad proste odcinanie atakowanych komputerów od Internetu.
Opis całego kontekstu projektu i wstęp do wydajnego przetwarzania pakietów okazał się na tyle długi, że tematyka samych algorytmów lock-less musi znaleźć swoje miejsce w następnym artykule “Portal do TAMA”.

