
Wstęp
"Efficiency is doing things right; effectiveness is doing the right things." -- Peter F. Drucker "Wydajność nie polega na skutecznym realizowaniu niepotrzebnej pracy." -- Moja nieskuteczna próba przekładu. *** "No code is faster than no code." -- Programmers of old. "Żaden kod nie jest szybszy od braku kodu." -- Czy jakoś tak.
Tymi dwoma trudnymi w przełożeniu aforyzmami zaczynam drugą część artykułu o systemie TAMA. Część pierwsza – Pierwotna Informatyka w Systemie TAMA – omówiła projekt oraz problemy z tworzeniem wydajnych programowo filtrów pakietów. Zakończyłem go obietnicą bliższego spojrzenia na algorytmy i na drogę, którą pokonywaliśmy, by dotrzeć do rozwiązania finalnego.
Przypomnienie sobie poprzedniego artykułu nie jest obowiązkowe – ale polecam, szczególnie końcówkę. Pierwsza część była też o wiele mniej techniczna od tej, która… sami zobaczycie. Będę wprowadzał część używanych przeze mnie pojęć i linkował do objaśnień tych, które będą poza zakresem artykułu.
Scena
Przypominajka: TAMA zawiera Filtr Pakietów, na który w momencie ataku przekierowujemy ruch z routerów brzegowych sieci w celu odfiltrowania syntetycznych pakietów należących do ataku od faktycznego ruchu użytkowników chronionej usługi. Dzięki temu faktyczny „Service Denial” ze skrótu DDoS nie będzie miał miejsca. Wewnętrznie nazywamy ten komponent GlaDDoS (inne komponenty: Aperture obserwuje ruch sieciowy, Chell to interfejs operatora służący do konfiguracji, system stoi na serwerach FizzlerXX, a Portal jest interfejsem dla klientów).
Filtrów jest więcej niż jeden – są wpięte w różne punkty sieci i sieć magicznie (poza zakresem artykułu) wybiera najlepsze z nich do przekierowania ruchu. Filtry mogą być wpięte w sieć kilkoma linkami 10GbE lub 40GbE/100GbE. Mogą jednocześnie obsługiwać kilka ataków na kilku różnych klientów.
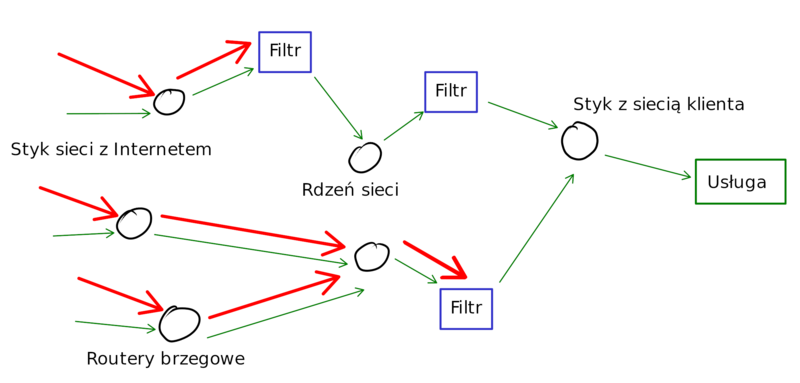
Filtry są autonomiczne – są geograficznie rozproszone i powinny działać również w trakcie ataku DDoS na infrastrukturę operatora. Komunikacja pomiędzy komponentami jest wtedy utrudniona lub może być niemożliwa. W takiej sytuacji, żeby mitygować jednocześnie kilka ataków na różne pojawiające cele, Filtry muszą dysponować pełną konfiguracją a priori.
Światło
Filtry działają pod kontrolą systemu Linux, który ma zaimplementowany stos protokółów TCP/IP. Potrafi rozmawiać z kartą sieciową i wystawia aplikacjom wygodny interfejs programistyczny. Programy mogą nim nawiązać połączenie, otrzymać odebrane z sieci dane i wygodnie je wysyłać. Aplikacja zwykle nie musi znać ani konfiguracji sieciowej, ani szczegółów działania protokołów.
Zwyczajowy sposób działania sieci w Linuxie opisywała część pierwsza artykułu. Jest wygodny, ale dla nas zbyt wolny. Z tego powodu sięgamy po bibliotekę DPDK, która pomija normalną implementację sieci w systemie, pozwola nam niskopoziomowo komunikować się z kartą sieciową, unikać kopiowania pamięci i przekraczania granicy user-kernel space. W zamian za wydajność, będziemy musieli nauczyć nasz komputer od nowa rozmawiać ze światem.
Obsługa całego ruchu na jednym rdzeniu procesora nie jest możliwa – potrzebne jest rozłożenie obciążenia. Przy pomocy DPDK konfigurujemy kartę sieciową tak, by dzieliła wchodzące pakiety na tyle kolejek, ile mamy dostępnych rdzeni. Sposób podziału nie jest jednak bez znaczenia i przekłada się na działanie algorytmów filtrowania.
Najprostszy jest algorytm karuzelowy (Round Robin), który kolejne pakiety przydzieli kolejnym rdzeniom, a gdy dojdzie do końca – zacznie ponownie od pierwszego. Zaleta: Ruch będzie zawsze równo podzielony, bez możliwości większego obciążenia żadnego rdzenia. Wada: tracimy możliwość korelowania informacji o połączeniu.
Sposób rozrzucania, z którego korzystamy, wymaga odrobinę wprowadzenia. Pakiety w Internecie mają zazwyczaj maksymalny rozmiar 1500B i składają się z 4 istotnych dla nas warstw:
- Ethernet + VLAN (komunikacja lokalna Router <-> Filtr): adresy src/dst MAC,
- IP (komunikacja klient-usługa): adresy src/dst IP,
- TCP/UDP (czasem ICMP; połączenie / strumień danych): porty src/dst,
- payload (np. protokół HTTPS, zapytania i odpowiedzi DNS, NTP, …)
Połączenie w pełni identyfikuje 4 elementowa krotka zbudowana z najważniejszych informacji warstwy IP oraz TCP/UDP: źródłowe i docelowe adresy IP (32 lub 128 bitowe) oraz źródłowe i docelowe porty (16 bitowe). Adres docelowy to adres chronionej przez nas usługi, któremu można ufać w 100%. Adres źrodłowy jest potencjalnie oszukanym adresem nadawcy. W ruchu powrotnym od usługi do klienta byłoby na opak – ale tego ruchu zazwyczaj nie analizujemy.
W pewnym sensie elementy krotki postawione koło siebie stanowią po prostu dużą liczbę, którą możnaby podzielić przez liczbę naszych rdzeni i z tego dzielenia wziąć resztę – która wskaże nam na którą kolejkę należy przekierować pakiet. Wtedy te same elementy krotki zawsze wskażą ten sam rdzeń – bez używania żadnej dodatkowej pamięci.
W praktyce, przed dzieleniem, by skonwertować krotkę na liczbę, użyjemy funkcji skrótu z odrobiną pieprzu:
- chcemy, by nawet drobna zmiana np. portu spowodowała całkowitą zmianę wyniku, dzięki czemu zmniejszymy szansę, że niektóre rdzenie dostaną znacząco więcej ruchu niż inne – nawet „podobny” ruch będzie równo rozłożony.
- chcemy uniemożliwić atakującym generowanie sztucznego ruchu w sposób, który wywoła większe obciążenie jednego rdzenia i ograniczy naszą faktyczną zdolność filtrowania.
Można też odrobinę zaszaleć i użyć wyłącznie fragmentów tej krotki. Np. samego źródłowego adresu IP – wtedy dany rdzeń będzie w stanie dość dokładnie ograniczyć ruch pochodzący z tego samego źródła, ale też będzie musiał obsłużyć cały ruch pochodzący z jednego (potencjalnie oszukanego) źródła.
Nie czarujmy się jednak, że mamy tutaj pełną kontrolę nad podziałem ruchu. Jesteśmy zaledwie drugim pomocnikiem wykidajły ustawiającym kolejkę chętnych do klubu. Ruch w pierwszej kolejności został podzielony na sieci w zależności od jej obciążenia, lub od tego, którym stykiem sieci dostał się do nas. Postawiliśmy więc pierwszą stopę w świecie nie-do-końca-poprawnych (lub ładniej: probabilistyczno-statystycznych) algorytmów. Przykładowo, nawet jeśli Filtr zgodnie z konfiguracją przytnie ruch pochodzący spoza Polski do 10Mbit/s to nie znaczy, że dokładnie tyle dotrze do usługi. To będzie zależało od liczby Filtrów biorących udział w mitygacji i aktualnej ścieżki ruchu w sieci.
Kamera
Linux, jądro systemu operacyjnego, z pomocą znajdującego się w procesorze modułu mapowania pamięci (MMU), przydziela działającym programom pamięć. Dba o to, by były odizolowane od siebie wzajemnie oraz od niego. Programy widzą swoją „wirtualną pamięć”, która jest przy każdej próbie dostępu konwertowana automatycznie na pamięć fizyczną za pomocą konfiguracji MMU. Zazwyczaj zarządzaną jednostką pamięci jest jedna strona o rozmiarze 4096B (4kB).
System może też być leniwy, lub wprost kłamać – obiecać pamięć, ale jej nie przydzielić. Przy pierwszej próbie zapisu do takiej pamięci wystąpi wyjątek, który przerwie pracę programu i dopiero wtedy system przydzieli faktyczną pamięć. Czasem, zanim to zrobi, inną stronę pamięci zapisze wcześniej na dysk (swap) lub postanowi zabić jakąś aplikację, by zwolnić pamięć.
Ten ogólny i uniwersalny mechanizm działa bardzo dobrze dla większości aplikacji. Niemniej w naszym szczególnym przypadku „kolejki pakietów” nie jest optymalny. Gdy potrzebujemy zaalokować paręnaście GB ciągłej pamięci na pakiety, to narzut z zarządzania małymi stronami 4k robi się znaczny: Konfiguracja MMU jest niepotrzebnie duża co sprawia, że pamięć podręczna procesora nie jest dobrze wykorzystywana.
Co więcej, maksymalny rozmiar pakietów w Internecie to zazwyczaj 1500B, czyli w jednej stronie pamięci zmieścimy ich 2,7. Co trzeci pakiet znajdowałby się na granicy dwóch stron, które fizycznie mogą leżeć w różnych miejscach i wymagają mapowania.
Gdy DPDK alokuje pamięć na kolejkę pakietów to sięga po tzw. Hugepages – strony 512-razy większe, o rozmiarze 2MB. Są one prealokowane, więc w trakcie dostępu nagle nie wystąpi przerywający pracy wyjątek, jest ich 512 razy mniej, więc o tyle są też mniejsze struktury MMU i cache procesora (TLB) przy dostępie do nich jest lepiej wykorzystywany. Łatwiejszą pracę ma też karta sieciowa, która pakiety będzie bezpośrednio umieszczała w naszej pamięci.
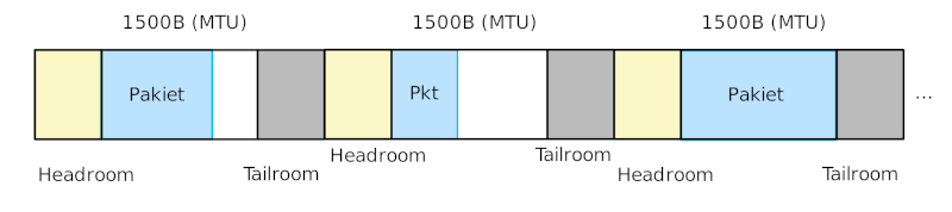
Pakiet zostaje zapisany w pamięci RAM za pomocą karty sieciowej poprzez jej interfejs PCI-e – bez udziału procesora. Następnie nasz program będzie ten pakiet analizował, potencjalnie modyfikował in situ, i informował drugą kartę sieciową, że może sobie pakiet z danej pozycji pobrać i wysłać.
Jesteśmy dosyć rozrzutni – dla uproszczenia kodu zakładamy, że wszystkie pakiety mają 1500B i zapewniamy sobie trochę miejsca przed pakietem (headroom) oraz za pakietem (tailroom) gdyby trzeba go było modyfikować. Headroom przyda się nam gdy będziemy umieszczać pakiety w tunelu GRE – co wymaga doklejenia przed nim dodatkowej warstwy protokołów GRE oraz IP. W ten sposób przehandlowujemy trochę cykli procesora w zamian za większe zużycie pamięci RAM.
Gdy skończy się miejsce na napływające pakiety – karta sieciowa zacznie zapisywać naszą kolejkę od początku nadpisując najstarsze wpisy.
Akcja
Filtry pobrały konfigurację, zaalokowały kolejki pakietów i skonfigurowały karty sieciowe. Czekają. Zaczął się atak. Wykrywamy go i włączamy przekierowanie ruchu. Routery przekierowują pakiety do najbliższych Filtrów. Karty sieciowe je odbierają i zapisują do kolejek.
Teraz na scenę wkracza uruchomiona na każdym powiązanym z kolejką rdzeniu pętla filtrująca – nasz właściwy Wykidajło. Zazwyczaj wprawdzie nie chroni dyskotek, tylko np. banki. Nasz bohater, obrońca przepełnionych klubów, w nieskończonej pętli:
- Odbiera informację o paczce stojących w kolejce pakietów.
- Dla każdego pakietu ustala jego konfigurację mitygacji w oparciu o jego cel.
- Wykonuje szereg testów, które mają odróżnić pakiety faktycznych klientów, od syntetycznego ruchu pochodzącego z ataku.
- Każdy pakiet dostaje opaskę na rękę z informacją: PASS (przepuść), DROP (odrzuć), SENDBACK (coś odeślemy by wykonać dodatkowy test).
- Modyfikujemy odpowiednio pakiety PASS i SENDBACK (np. zmieniamy VLAN, dodajemy tunel GRE).
- Zlecamy wysyłkę paczki pakietów, które powinny polecieć dalej – z powrotem do routera i do chronionego serwera. Pozostałe zostaną nadpisane nowymi pakietami ze względu na sposób działania bufora.
- Odnotowujemy statystyki ruchu – wszyscy kochają raporty.
Ciąg działań wykonywanych na pakiecie nazywany potokiem (a częściej pipeline).
Potok podczas pracy korzysta z kilku różnych rodzajów danych:
- pamięć własna read-write (RW): kolejka pakietów, stan mechanizmów filtrowania, statystyki pracy,
- pamięć wspólna read-only (RO): konfiguracja mitygacji, listy GeoIP.
Rozwinięcie
Kooperacja
Poszczególne rdzenie są oprogramowane w taki sposób, by nie wchodziły sobie w drogę przez zachowanie jednej podstawowej zasady: nie istnieje wspólna pamięć RW. Wątek może zapisywać wyłącznie w obrębie swojego obszaru pamięci, a z pamięci wspólnej – tylko czytać. Wspólna pamięć RW wymaga zazwyczaj używania synchronizacji dostępu (np. mutex), a synchronizacja sprawia, że zysk z dodawania kolejnych rdzeni szybko zaczyna spadać – zgodnie z prawem Amdahla. Naszym celem było dążenie do stu procent równoległego przetwarzania.
Co ciekawe wspólna w programie jest między innymi sterta (heap). To sprawia, że wszystkie standardowe operacje alokujące pamięć (malloc, new, std::vector::push_back, …) synchronizują do niej dostęp – a tego w pętli przetwarzania pakietów nie chcemy robić. Z tego powodu, wszelką pamięć będziemy chcieli zaalokować raz – podczas startu aplikacji. Musi nam to wystarczyć.
Niemniej nasz wykidajło nie może istnieć zupełnie w oderwaniu od reszty wszechświata:
- co jakiś czas (często) management zmienia zasady wpuszczania ludzi do klubu (ie. zmienia się konfiguracja mitygacji, również w trakcie mitygacji),
- musi raportować regularnie ile i jakich osób wpuścił lub nie.
Oba te problemy rozwiązujemy w taki sam sposób – centralnym wątkiem zarządzającym i atomicznym podmienianiem wskaźnika na pamięć:
- Wątek zarządzający odbiera po sieci nową konfigurację i alokuje struktury (on jeden może), buduje klasy, vectory, mapy i listy.
- Podmienia znajdujący się w pamięci wskaźnik na konfigurację tak, by wskazywał na świeższą wersję. Od tego momentu, każda pętla obsługi gdy zacznie analizować nowy pakiet zacznie korzystać z nowej konfiguracji.
- I… powinien zwolnić starą pamięć konfiguracji – ale nie może tego zrobić od razu. Z tej pamięci mogą jeszcze korzystać pętle przetwarzające pakiety.
- Pętle zwiększają pewien licznik, który nazywamy „numerem epoki”. Robią to wtedy kiedy nie używają żadnych wspólnych zasobów – np. przed podjęciem kolejnej paczki pakietów.
- Wątek główny odnotowuje dla każdej pętli ten numer i czeka aż każda z nich go zwiększy o jeden.
- Gdy się to stanie, oznacza to, że każda pętla zakończyła co najmniej jedną epokę, tj. będzie na pewno korzystać z nowej konfiguracji.
- Wątek główny może zwolnić starą pamięć.
Dzięki temu podejściu pętle przetwarzające pakiety muszą wyłącznie raz na pętlę skorzystać z atomicznego wskaźnika na konfigurację – co jest tanią operacją porównując do klasycznego podejścia typu RWLock lub Mutex.
Tak samo można rozwiązać temat statystyk:
- Wątek główny co ~10 sekund tworzy nową strukturę na zsumowane statystyki.
- Każdy wątek ma dwie kopie struktury statystyk. Wątek główny może wyzerować nieużywane aktualnie statystyki i podmienić za te obecnie wypełniane.
- Poczeka aż zwiększy się numer epoki, tj. wątki przestaną zapisywać do poprzednich statystyk.
- Zsumuje statystyki wątków tak, by uzyskać jeden zbiór statystyk dla Filtra.
- Zserializuje i wyśle statystyki przez sieć do centralnego komponentu TAMA.
Bardziej wszechstronny sposób komunikacji mógłby polegać na użyciu kolejek producent-konsument typu lockless i do pewnego rodzaju zdarzeń może to być niezbędne. Niemniej jak zwykle – zgodnie z motto artykułu – wybieramy lżejsze rozwiązanie tam gdzie to jest możliwe.
Konfiguracja
Niektóre ataki są dość oczywiste, ale inne czasem trudno odróżnić od faktycznego ruchu do usługi. Zależnie od tego co chronimy (czy jest to serwer DNS, NTP, serwer HTTPS lub może korporacyjna sieć firmowa) stosujemy odpowiednio dostosowaną do sytuacji konfigurację mitygacji.
Konfiguracja mitygacji to przede wszystkim:
- Adres IP chronionego obiektu razem z maską, np. 193.17.40.0/22 (czyli adresy od 40.0 do 43.255). Często są to konkretne serwery (/32), czasem małe podsieci, bardzo rzadko większe sieci, maksymalnie /22 (1024 adresy).
- Informacje które mechanizmy są włączone i mają działać (wyłączony mechanizm nie obciąża Filtra).
- Konfiguracja prostych mechanizmów dla portów i protokołów (chroniących m.in. przed atakami typu reflected NTP/DNS).
- Konfiguracja podejrzanych (np. znane botnety) źródłowych adresów IP,
- Konfiguracja adresów które są niezbędne do działania usługi i nie powinny być blokowane,
- Konfiguracja filtrowania geo – lista krajów (dopuszczanie, odrzucanie i limitowanie).
- Sygnatury L3 (adresy)/L4 (protokół, porty) które precyzyjnie potrafią przepuszczać/odrzucać/limitować ruch.
Dla każdego trafiającego do nas pakietu, musimy ustalić, którą konfigurację zastosować. Interesujące Filtr pakiety mają nagłówek protokołu IP, który zawiera docelowy adres – np. 193.17.41.115. Ten adres musimy odpowiednio dopasować do struktury przechowującej konfigurację.
Konfiguracja jest hierarchiczna. Jeśli mamy dokładny wpis, tj. 193.17.41.115/32 – to go użyjemy. Jeśli nie, zaakceptujemy wpis dla całej sieci 193.17.41.0/24. Jeśli i takiego nie będzie, dobry będzie wpis ogólniejszy 193.17.40.0/22. Wybieramy od najdłuższej maski (najdokładniejsze dopasowanie) do najkrótszej (najbardziej ogólne). Dzięki temu operatorzy w konfiguracji mogą posługiwać się większymi segmentami sieci. Taki sposób dopasowania nazywa się LPM – Longest Prefix Match i jest zazwyczaj kojarzony z routingiem w sieciach IP.
Sprawdzenie przynależności adresu IP do sieci to operacja logiczna:
- Wygeneruj mapę bitową z maski (/22): 11111111111111111111110000000000
- Wykonaj logiczny AND adresu IP oraz maski, by uzyskać adres sieci:
-
11111111.11111111.111111 00.00000000 Maska
-
11000001.00010001.001010 01.01110011 Adres
-
11000001.00010001.001010 00.00000000 Maska & Adres = Adres sieci
-
- Na koniec sprawdzamy czy wyliczony adres sieci zgadza się z tym z konfiguracji.
Wpisów konfiguracyjnych jest paręset, w sumie parędziesiąt tysięcy adresów. Prostym rozwiązaniem mogłaby być lista wpisów (posortowana od szczegółowych do ogólnych), przez którą przechodzimy dla każdego pakietu, wykonujemy powyższą operację logiczną i jak znajdziemy wpis – zatrzymujemy wyszukiwanie. To naiwne rozwiązanie miałoby złożoność obliczeniową O(n) – dla n równego liczbie wpisów konfiguracyjnych.
Tego rozwiązania nigdy nie zaimplementowaliśmy. Było dość jasne, że nie będzie się odpowiednio skalować. Mieliśmy inny, równie prosty, pomysł:
- Posortuj dane od ogólnych (krótkie maski) do szczegółowych (aż do /32).
- Utwórz pustą tablicę asocjacyjną (hashmap), której kluczem jest pełny adres, a wartością wskaźnik na konfigurację.
- Dla każdego wpisu w konfiguracji, rozwiń adres sieci z maską na indywidualne znajdujące się w niej adresy (/32) i wstaw je do hashmapy.
- Jeśli w Hashmapie jest już wpis – nadpisz go; aktualnie umieszczany jest albo tak samo istotny (ta sama maska), albo bardziej istotny (dłuższa maska).
Takie rozwiązanie pozwoliło zmniejszyć złożoność obliczeniową odpytania o konfigurację do złożoności O(1) – kosztem dłuższego czasu inicjalizacji i rozmiaru struktury. Jak wpada pakiet, liczymy hash adresu IP (przyda się i tak później; można go policzyć raz i zapamiętać), a następnie skaczemy w odpowiednie miejsce w hashmapie i… niby jest ok.
Dużą zaletą rozwiązania jest prawdziwy ogrom gotowych implementacji Hashmapy, zaczynając od std::unordered_map, przez Boosta, aż po wiele innych, więc kod rozwiązania jest bardzo prosty.
Główna wada? Otóż maska /22, która oznacza 1024 adresy, ma sens dla IPv4. Ale dla IPv6 w użyciu są maski /48 (2^(128-48) -> 1208925819614629174706176 adresów) lub /64 (18446744073709551616) i nie mamy ani dość pamięci, ani czasu, by je rozwijać. Duże struktury danych nie za dobrze współpracują też z pamięcią cache procesora – w poprzednim artykule wspominałem, że RAM jest w pewnym sensie wolny.
Niemniej zanim zmieniliśmy to rozwiązanie trochę podziałało produkcyjnie i ogólnie dawało radę. Szczególnie, że zwykle trwają ataki na małą liczbę adresów docelowych i pojedyncze, powtarzalne zapytanie do dużej hashmapy może się cache’ować.
Chciałbym zwrócić uwagę na pewien powracający motyw: struktura, którą zbudowaliśmy, jest po jej utworzeniu niemodyfikowalna, ale i dzięki temu nie wymaga synchronizacji. Wyszliśmy od klasycznej Hashmapy z takimi funkcjami:
- insert(key, value) O(1) (koszt zamortyzowany)
- delete(key) O(1)
- query(key) O(1)
A skończyliśmy z niemodyfikowalną strukturą:
- init(sorteddata) O(n)
- query(key) O(1)
Po wykonaniu inicjalizacji, funkcje insert i delete należące do znajdującej się „pod spodem” hashmapy nie mogą być swobodnie używane (ze względu na wymóg zachowania konkretnej kolejności wstawianych elementów). Również wykonywanie zmian danych w trakcie gdy inne wątki wykonują operację query byłoby niebezpieczne. Strukturę buduje zawsze główny wątek, a potem udostępnia potokom, które nie synchronizują do niej dostępu – ponieważ wyłącznie ją czytają.
Zanim opowiem o LC-Trie, rozwiązaniach ze stajni DPDK, IPv6 i naszym finalnym rozwiązaniu, przyjrzyjmy się pokrewnemu problemowi.
Listy reputacyjne
TAMA wykorzystuje listy adresów IP do kilku celów, w tym dwóch podstawowych:
- wczesnego odrzucania ruchu od źródłowych adresów IP o niskiej reputacji (znane sieci botnet, lub np. znane źle skonfigurowane serwery NTP)
- wczesnego akceptowania adresów, które nie powinny być zablokowane (wymagane do pracy serwery DNS, NTP, itp.)
W przeciwieństwie do konfiguracji, listy reputacyjne zawierają o wiele więcej adresów IP, a także nie mają powiązanych z nimi wartości – po prostu adres jest na liście, lub nie. Naiwne rozwiązanie tego tematu to zamiana Hashmap, użytego do konfiguracji, na Hashset (unordered_set). Hashset to podstawowa struktura, która jest odpowiednikiem matematycznego zbioru. Przechowuje unikalne wartości bez konkretnej kolejności i potrafi weryfikować czy element został do niej dodany – czy nie. Złożoność operacji query wynosi O(1), natomiast czas inicjalizacji może być ogromny i zależy od danych. Rozmiar struktury w (wolniejszej niż chcemy) pamięci będzie również duży i nie będzie dobrze współpracował z pamięcią podręczną CPU.
Nasz problem jest konkretny – chcemy przechowywać adresy IP – 32 bitowe liczby. Nasza struktura może być prostsza jeżeli nie pracujemy z dowolnymi typami danych: W szczególności nie potrzebujemy używać funkcji skrótu ani nie potrzebujemy przechowywać całych, często podobnych, adresów IP (10.0.0.1, 10.0.0.2, 10.0.0.3, …).
Wszystkich adresów IPv4 jest „jedynie” 2^32 = 4 294 967 296. Gdyby przynależność każdego adresu do listy zakodować pojedynczym bitem potrzebowalibyśmy 2^32/8 = 536 870 912 = 536MB pamięci na obsłużenie całego Internetu. Wcale nie tak dużo jeśli list jest zaledwie kilka, a operacja query będzie potrzebowała wyłącznie jednego odczytu pamięci RAM, by zweryfikować obecność adresu w liście. Biblioteka standardowa C++ posiada też klasę bitset, którą możemy taką strukturę bardzo szybko zaimplementować.
Nierozwiązane problemy pozostają trzy: długi czas inicjalizacji struktury, brak wsparcia dla IPv6 (10^37 bajtów RAM to za dużo) i słabe wykorzystanie cache’u CPU. Niemniej, ta struktura może działać i ma pewne zalety.
Na potok wpada pakiet, sprawdzimy powiązaną konfigurację, w niej znajdziemy listy – bitsety powiązane z akceptowanymi i odrzucanymi pakietami. Spojrzymy w pamięć pod odpowiednim adresem i znajdziemy tam albo 0, albo 1 – i adekwatnie zaakceptujemy pakiet, odrzucimy lub puścimy dalej przez potok filtrujący. Algorytm jest w 100% poprawny.
Czy tą strukturę można jakoś zoptymalizować? Zazwyczaj większość bitów będzie równa 0. Może być kuszące takie obsłużenie wirtualnej pamięci, żeby całe jej strony (4096kB), które są całkowicie wypełnione zerami wskazywały tą samą stronę fizycznej pamięci – na poziomie MMU. Ale trzeba uważać, by dostęp do tych stron nie wywoływał Page Fault, który utopi wydajność.
Rozkwit filtrów
Powiedzmy, że nie potrzebujemy w 100% poprawnego algorytmu. Czy możemy wtedy naszą strukturę jeszcze zoptymalizować?
Powiedzmy, że możemy zaakceptować błędy typu false positive, ale nie false negative. To znaczy, że gdy struktura odpowie, że adresu nie ma na liście to faktycznie w 100% go nie ma. Gdy powie, że jest to… z jakimś kontrolowanym prawdopodobieństwem może kłamać.
Zmodyfikujmy nasz bitset. Spróbuję koncept przedstawić na uproszczonym przykładzie z równomiernie rozłożonymi adresami IP: Gdyby moja lista maksymalnie mogła mieć 10 adresów i akceptowałbym prawdopodobieństwo błędu 50%, to wystarczyłoby mi zaledwie 20 bitów pamięci. Mapuję adresy na przedział liczb 0-19 (np. resztą z dzielenia, %) i ustawiam bity na „1” dla wszystkich 10 adresów z listy. Średnio 50% bitów będzie zapalone (niektóre mogą się pokryć). Jeśli będę odpytywał strukturę o losowe adresy, to z prawdopodobieństwem 50% trafię w ustawione bity. Ale jeśli trafię w bit 0 to mam 100% pewności, że ten adres nie znajduje się w oryginalnej liście.

Jeśli zamiast reszty z dzielenia użyję 2-3 niezależnych, szybkich funkcji skrótu (np. MurmurHash3), a każda z nich zapali potencjalnie inny bit dla tego samego adresu, to wymyślę na nowo filtr Blooma. W przykładowej zmierzonej konfiguracji mogę za pomocą 5MB pamięci uzyskać błąd zaledwie 0.49% dla list do 2.5mln wpisów używając trzech funkcji skrótu. Lub 0.5% dla 200k wpisów z jedną funkcją skrótu.
Jakie są zalety i wady? Cała pamięć filtra Blooma zmieści się w pamięci cache procesora – nie będzie trzeba robić tak wielu drogich wycieczek na kości DIMM. Odpowiedzi będą bardzo szybkie (dziesiątki query/s per rdzeń). Mogę dostosować zużycie pamięci i prawdopodobieństwo błędu do konkretnych potrzeb. Ma stały rozmiar i mogę dodawać nowe rekordy bez alokowania lub kopiowania pamięci – a nawet atomicznie bez używania synchronizacji. Z drugiej strony inicjalizacja filtra wymaga rozwijania adresów IP sieci i kosztuje czas. No i popełnia błędy typu false positive.
Filtr Blooma można stosować tam, gdzie na jego błędy pozwala nasz biznes – tzn. przypadek użycia. W przypadku mitygowania ataku DDoS okazjonalne przepuszczenie pakietu należącego do ataku jest mniejszym błędem niż nieprzepuszczenie rzeczywistego pakietu potrzebnego do sfinalizowania transakcji klienta. Dlatego można by go użyć do listy zaufanych adresów (i okazjonalnie np. z P=0.1% zaufać czemuś niepotrzebnie), ale nie do negatywnej listy reputacyjnej odrzucającej pakiety.
Można go zawsze zastosować jako wstępny filtr błyskawiczny przed odpytaniem innej (100% poprawnej, ale wolniejszej) struktury. Szczególnie gdy oczekujemy, że w większości przypadków informacja na liście się nie znajdzie. Wtedy każda negatywna odpowiedź filtra sprawi, że nie będziemy musieli sięgać do wolnej struktury. Jeśli natomiast filtr Blooma uzna, że adres może znaleźć się na liście – wtedy weryfikujemy informację u źródła. Bloom działa bez problemu dla IPv6.
Używamy filtrów Blooma również gdy musimy krótkoterminowo zapamiętać, że widzieliśmy już dany adres IP. Przykładowo podczas mitygacji ataków SYN flood. Przepuszczamy ruch do klienta tylko wtedy gdy wcześniej poprawnie zweryfikowaliśmy, że źródłowy adres IP nie jest podrobiony, a to wymaga przechowywania stanu. Dzięki filtrom Blooma możemy ten stan przechowywać bez alokowania pamięci. „Krótkoterminowa pamięć” wymaga jednak pewnej sztuczki – bo raz dodanego do filtra adresu nie można już nigdy usunąć. Używamy po prostu dwóch filtrów – A i B. Co określony czas, np. 30s, filtry są rotowane: filtr A jest zerowany i zostaje zamieniony z filtrem B. Adresy dodawane są zawsze do obu filtrów jednocześnie, tak by dodany adres był pamiętany przez 30-60s – zależnie od momentu jego wstawienia.
Koniec praktyk
Dobra, dobra. Zabrnęliśmy dosyć daleko bez udzielania odpowiedzi na pytanie dlaczego ani opisany mechanizm dopasowania konfiguracji, ani mechanizmy list nie są obecnie przez nas używane (w przeciwieństwie do Blooma). Głównie z dwóch powodów: IPv6 i GeoIP. Rozwijanie masek i indywidualne traktowanie adresów nie skaluje się kiedy adresy są 128 bitowe lub adresy pokrywają praktycznie cały Internet.
Problem routingu IP i dopasowań LPM ma dwa kanoniczne rozwiązania. Jednym jest sprzętowa trójstanowa pamięć adresowana zawartością (TCAM) używana m.in. w routerach i switchach. W przeciwieństwie do znanej programistom pamięci RAM, w której znając adres można poznać przechowywaną w pamięci wartość, pamięć ta szuka po wartości i zwraca jej adres. Trójstanowość pozwala na oznaczenie niektórych przechowywanych bitów nie jako 0 lub 1 (które będzie musiało pasować do zapytania), ale jako „X” – wartość bez znaczenia – co pozwala zaimplementować maskę.
Nasze rozwiązanie jest programowe, dlatego TCAM stanowi wyłącznie ciekawostkę. Drugie powszechne rozwiązanie (używane np. przez jądro Linux) to drzewo Trie, a konkretnie Level Compressed Trie. Linux jest używany w wielkich serwerach, ale i w domowych routerach, które mają 8MB RAM. Struktura ta musi być dość oszczędna i uniwersalna – a my jesteśmy gotowi poświęcać pojemność RAM, by oszczędzać cykle procesora – lub dostępy do RAM. Z tego powodu przyjrzyjmy się innej implementacji.
Ciekawe rozwiązanie i ostatecznie bardzo podobne do używanego przez nas jest zaimplementowane w bibliotece DPDK – osobno dla IPv4 i IPv6. Dla IPv4 adres jest dzielony na najbardziej znaczące 24bity oraz 8 bitów ostatniego oktetu: [a.b.c][d]. Podczas operacji wyszukiwania niezbędne są wyłącznie dwa dostępy do pamięci:
- Wyszukujemy 24 bity w dużej tabeli. Jeśli wpis jest oznaczony jako nieużywany – nie mamy wpisu dla danego adresu.
- Jeśli jest używany to albo od razu mamy odpowiedź na nasze zapytanie (maska maksymalnie /24), albo wykonujemy dodatkowe query w zagnieżdzonej tabeli za pomocą [d].
Dodawanie wpisów /24 jest łatwe – wymaga tylko jednego wpisu w dużej tabeli. Wpisy ogólniejsze wymagają oznaczenia wielu pozycji, np. /8 wymaga oznaczenia 65536 różnych adresów /24. Wpisy dłuższe niż /24 wymagają podłączenia pod wpis dodatkowej tabeli z 256 pozycjami. Rozwijamy więc maski, ale w kontrolowany sposób.
Struktura ta jest zoptymalizowana do celów routingu gdzie maski dłuższe niż 24 bity występują bardzo rzadko – inaczej jest w naszej konfiguracji, gdzie najkrótsze są długości 22, a bardzo wiele wpisów dotyczy pojedynczych adresów IP. Domyślnie struktura DPDK zajmuje 64MB RAM i obsługuje tylko 256 różnych podsieci /24 z wpisami dłuższymi od 24 bitów.
Istnieje też podobna struktura dla IPv6, ale ma więcej podziałów: 24 bity, a potem maksymalnie 13 podziałów po 8 bitów (8*13+24=128).
Nasze rozwiązanie powstało jako próba opisania problemu wyszukiwania za pomocą automatów skończonych, ale ostatecznie okazało się podobne do rozwiązania DPDK – tylko skrojonego pod nasze potrzeby. Jest to proste n-rzędowe drzewo trie. Jest zaimplementowane w formie parametryzowalnego szablonu C++, gdzie parametr wybiera rząd – tj. liczbę dzieci każdego węzła.
Przykładowo do przechowywania konfiguracji systemu używamy n=8, co dzieli adresy IP na 4 zagnieżdzone poziomy: [a].[b].[c].[d], a każdy poziom ma 2^8=256 dzieci. Ten podział podczas query wymaga 4 dostępów do pamięci, ale zajmuje tej pamięci o wiele mniej niż tabela DPDK (dla naszej konfiguracji), dzięki czemu mieści się w pamięci cache procesora i jest bardzo szybka. Działa też dla IPv6 dzieląc adres na maksymalnie 16 zagnieżdzonych tabel. Możliwe, że nierówny podział na 16+8+8 bitów [a.b].[c].[d], byłby szybszy (3 dostępy), ale zwiększyłby złożoność kodu, a struktura jest obecnie wystarczająco szybka.
Do przechowywania tabel GeoIP, mapujących adresy IP na identyfikatory krajów parametr n=8 zużywa za dużo pamięci RAM i konieczne jest zastosowanie podziału n=4.
Własne rozwiązanie było przydatne również wtedy jak okazało się, że query typu LPM nie zawsze jest dla nas wystarczające. W jednym miejscu, gdy przypisujemy ruch sieciowy do obiektów, potrzebujemy otrzymać informacje o każdym obiekcie w systemie TAMA obejmującym dany adres IP. W tym celu zmodyfikowaliśmy naszą strukturę tak, by dłuższe maski nie nadpisywały całkowicie informacji o krótszych podczas inicjalizacji. Natomiast query wywołuje callback z każdym dopasowanym do adresu obiektem (aby uniknąć alokacji listy odpowiedzi).
Mechanizmu użyliśmy również w listach reputacyjnych. Pozwoliło nam to zredukować liczbę dostępów do pamięci: zamiast kilku zapytań i binarnych odpowiedzi „należy / nie należy”, możemy na jedno zapytanie uzyskać maskę bitową wskazującą listy, do których należy adres.
Stan przycinania ruchu
Większość poruszonych algorytmów – poza filtrami Blooma w filtrze SYN – cechuje bezstanowość, czyli luksus, na który nie zawsze można sobie pozwolić. Ostatni mechanizm, który chciałbym omówić, to stanowy mechanizm przycinania ruchu – w oparciu o kraj pochodzenia, adres źródłowy lub np. ID reguły L3/L4 – zależnie od potrzeb.
Punktem wyjściowym jest powszechnie znany algorytm Token Bucket Filter (TBF), który ogranicza przepustowość uwzględniając nierównomierny charakter ruchu sieciowego – występowanie serii pakietów przedzielonych dłuższą ciszą. Algorytm zdefiniowany jest następująco:
- Dany jest kubeł (bucket) o pojemności M tokenów.
- Co sekundę do kubła dodajemy T tokenów.
- Jeśli kubeł jest już pełen, nadmiarowe tokeny są odrzucane.
- Kiedy pojawia się pakiet do transmisji:
- Jeśli w kuble jest token, zużywamy go i przekazujemy dalej pakiet.
- Jeśli w kuble nie ma już tokenów pakiet jest odrzucany.
Algorytm ostatecznie ograniczy transmitowaną liczbę pakietów do co najwyżej T pakietów na sekundę, ale dopuści transmisje M pakietów w serii. Jeśli chcemy ograniczać liczbę bajtów, a nie liczbę pakietów, wtedy odrzucamy z kubła liczbę tokenów zależną od rozmiaru pakietu i reszta algorytmu jest bez zmian.
Przy takiej definicji algorytmu może się wydawać, że dla każdego limitowanego adresu musimy przechowywać stan, który składa się z aktualnej liczby tokenów w kuble, a wątek musi co sekundę iterować przez wszystkie przechowywane kubły i aktualizować ich liczbę tokenów. Jeśli nie alokuję danych dynamicznie, tylko chcę przygotować od razu setki kubłów – wymagałoby to bardzo dużo pracy nad utrzymaniem stanu.
Alternatywnie, dla każdego limitowanego adresu można by przechowywać:
- czas ostatniej aktualizacji stanu (ostatniego pakietu),
- liczbę aktualnych tokenów w kuble.
Wtedy stanem możemy się zainteresować dopiero kiedy pojawi się pakiet do obsługi: porównamy czas do aktualnego, wyliczymy liczbę tokenów do dodania, zwiększymy liczbę tokenów, skonsumujemy ile potrzeba i odrzucimy lub przekażemy pakiet.
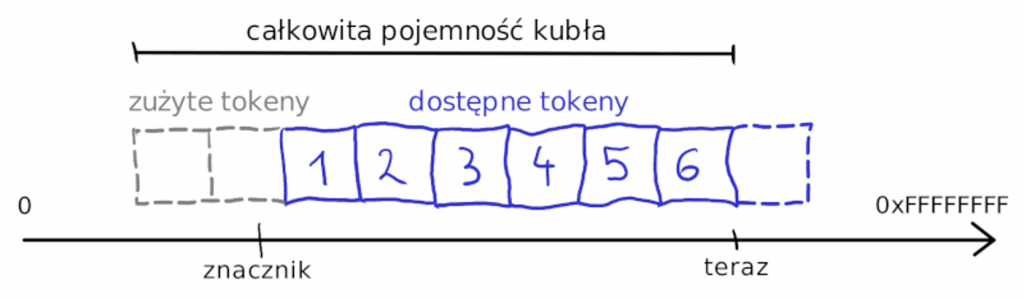
Natomiast jak się głębiej zastanowić to nie musimy przechowywać liczby tokenów w kuble. Można ją zawsze wyrazić jako różnicę w zapisanym czasie do czasu aktualnego: (now – state_time) / token_factor = tokens. Przechowujmy więc wyłącznie znacznik czasu – 32 bitową liczbę z rozdzielczością mikrosekundową. Algorytm przekazania pakietu będzie następujący:
- Odczytaj znacznik czasu dla danego adresu.
- Jeśli różnica pomiędzy znacznikiem, a aktualnym czasem wskazuje na więcej dostępnych tokenów niż M (pojemność kubła), przesuń znacznik tak, by dostępne było dokładnie M tokenów.
- Wylicz o ile trzeba popchnąć znacznik do przodu żeby przesłać pakiet. Jeśli przesunie to znacznik w przyszłość – brakuje tokenów, nie przesuwaj znacznika i odrzuć pakiet.
- W przeciwnym wypadku można wysłać pakiet i przesunąć znacznik.
Zapewne nie pierwsi implementujemy TBF w ten sposób, ale w Internecie nie znalazłem dotychczas takiego opisu i na pewno nie jest to popularna metoda.
Algorytm jest znany; potrzebujemy 4 bajtów pamięci per reguła, adres lub kraj. Mamy ten sam problem co wcześniej – nie możemy dynamicznie zaalokować pamięci w zależności od tego ile adresów musimy przycinać. Uciekamy więc znowu do podejścia probabilistycznego:
- Alokujemy na stan tabelę np. 2^20 rekordów, czyli zajmującą 4MB pamięci RAM.
- Podobnie jak w hashmapie, lub filtrach Blooma rzutujemy adres IP na tą przestrzeń – np. funkcją hashującą (z pieprzem). Jeśli hash dla tego adresu był już wyliczony wczesniej to teraz będzie użyty ponownie.
Może tu wystąpić kilka niedokładności. Kilka adresów IP może mieć pecha i wylosuje tą samą komórkę w pamięci – ich sumaryczny ruch zostanie wtedy przycięty zgodnie z konfiguracją. Komórka pamięci długo będzie nieużywana (ponad 70 minut) i kiedy pojawi się pierwszy pakiet znacznik czasu może się zawinąć i zamiast wskazać maksymalnie pełny kubeł (M tokenów) wskaże nam pechowo kubeł pusty. Pierwszy pakiet w takiej sytuacji zostanie odrzucony, ale kolejne będą już limitowane zgodnie z konfiguracją.
Niedokładność wynika też z podziału ruchu na routerach na poszczególne Filtry GlaDDoS oraz podziału ruchu na wątki.
Ograniczamy rozmiar pamięci nie tylko ze względu na cache, stan RW jest przechowywany per wątek. Gdyby TBF zajmował 100MB, w użyciu były 4 takie struktury, a system pracował na 32 rdzeniach – sumarycznie zajęlibyśmy 12.8GB RAM tylko na przycinanie ruchu.
Mierz dwa razy, tnij raz.
Optymalizacja oprogramowania to skomplikowany temat. Niektóre przetestowane rewelacyjne pomysły, które miały przynieść gigantyczne przyrosty wydajności, okazały się niemierzalne w skutkach (a komplikowały kod). Inne rozwiązania, które wydawały się zbyt proste by działać, były z nami długo – lub są do teraz.
Ciekawym przypadkiem małej zmiany, która niespodziewanie miała bardzo duży negatywny efekt było pewne czyszczenie kodu. Przenieśliśmy zmienną globalną do wnętrza jedynej używającej jej funkcji i oznaczyliśmy jako zmienną statyczną. Semantycznie taka zmiana na nic nie wpływa. Kompilator jednak zgodnie z życzeniem C++11 implementuje thread-safe inicjalizację zmiennych statycznych. Co oznacza użycie globalnego locka do synchronizacji inicjalizacji i każdorazowej weryfikacji czy zmienna jest już zainicjalizowana. Wydajność nagle znacząco spadła. Na szczęście z pomocą przyszedł profiler, który pozwolił znaleźć winowajcę w innym miejscu niż ktokolwiek się spodziewał.
Jeżeli wydajność oprogramowania jest istotna, bardzo dobrze jest zbudować proces w którym jest ona obserwowana w sposób ciągły. Na przykład, po każdej zmianie kodu, uruchamiać automatycznie testy wydajnościowe sprawdzające czy wydajność się zmieniła. Warto też ustalić, jaka wydajność będzie dla nas „wystarczająca”. Nie warto dać się porwać sztuce optymalizacji wyłącznie dla samej przyjemności poprawiania szybkości kodu.
Jeśli chodzi o software: mierz non-stop, tnij dopóki musisz.
Zakończenie
Implementacja pakietowego wykidajły do odpierania ataków DDoS, pomimo użycia wielordzeniowych serwerów wyposażonych w setki GB pamięci często przypominała mi programowanie 8-bitowych mikroprocesorów.
Rozwiązywany problem jest wymagający i dlatego pomimo o wiele większych zasobów – cały czas czuć ich granice. Oczywiste rzeczy, do których jesteśmy przyzwyczajeni, nie są dostępne:
- OS nie obsłuży za nas komunikacji ze światem,
- pamięć niby jest, ale nie można jej swobodnie używać,
- również z tego powodu nie można wprost użyć wielu gotowych, uniwersalnych struktur danych – klocków, z których składaliśmy każdy program,
- GDB działa, choć niektóre problemy mogą magicznie wystąpić tylko gdy nie jest podłączony do aplikacji.
Do tego dochodzą problemy z równoległym przetwarzaniem np. wyścigi. Te w świecie mikroprocesorów pojawiają się rzadziej, głównie gdy rozmawia ze sobą kilka niezależnych układów.
DPDK jest dobrą biblioteką. Nie trzeba pisać sterowników PCI-e, różne moduły rozwiążą podstawowe problemy i tylko czasem system zachowa się dziwnie – np. nie wstanie na danej konfiguracji rdzeni ze względu na konkretną architekturę NUMA komputera. Uruchamianie rozwiązania na pełnym Linuxie też pozwoli na użycie kontenerów i innych ułatwiaczy.
W takiej sytuacji dobrze sprawdziły się oba motta tego artykułu. Zawsze najszybszym sposobem na synchronizację wątków programu, okazało się przyjęcie takiej architektury, która pozwalała ich w ogóle nie synchronizować. Niewykonywanie kodu, którego nie trzeba wykonywać, jest po prostu szybsze od najszybszego wykonywania zbędnych operacji.
W motto wpisują się też struktury lock-less, trochę specjalistyczne i dlatego pewnie ciągle dość mało znane. Również one uzyskują często swoje własności przez rezygnację z uniwersalizmu lub wygody użycia. Czasem mają dziwne ograniczenia, ale nie są potworne.
Czasem trzeba było zrobić kilka kroków wstecz od zwyczajowo wykorzystywanego rozwiązania (typu TBF z periodycznym dodawaniem tokenów do kubłów) i zastanowieniu się czy optymalizujemy właściwe rozwiązanie. Czy warto analizować protokół NTP, by odróżniać pożądany ruch, od trwającego ataku typu reflected NTP (dużo pakietów z portem źródłowym równym 123) na serwer HTTP? Może wystarczy wstawić na listę reputacyjną jeden dopuszczony serwer NTP i resztę, po wykryciu prostego przekroczenia progu – odrzucić? Może jeśli serwer HTTP utraci dostęp do NTP na czas trwającego 30 minut ataku to jego zegar nie straci dokładności w znaczący sposób? Może nawet możemy odrzucić cały ruch UDP – jeśli usługa działa wyłącznie na TCP.
Jedno podejście nie wyklucza zresztą drugiego. Naprawdę duże ataki, w rozumieniu Mbps/Mpps, zazwyczaj zbudowane są z prostego ruchu sieciowego. Skomplikowane ataki na wyższe warstwy protokołów trudniej jest generować i zazwyczaj wymagają poprawnego, nie oszukanego adresu źródłowego (a wtedy działają listy reputacyjne lub WAFy). Filtry mogą się dostosować i wraz z poziomem ruchu automatycznie uruchomić inne mechanizmy filtrowania.
Przedstawiony koncept do tej pory się sprawdził – system działa produkcyjnie już od kilku lat. Dziennie obserwuje kilkadziesiąt zdarzeń, a Filtr GlaDDoS mityguje paręnaście większych i mniejszych ataków DDoS.
 |
 |


