Ataki DDoS (czyli odmowa dostępu do usług) są już nierozłączną częścią Internetu, bez względu czy jako użytkownicy sobie z tego zdajemy sprawę, czy nie. Zasada działania tego typu ataku polega na wysyceniu określonych zasobów po stronie serwera świadczącego usługę. Jeśli nie działa jakaś usługa, lub strona w sieci, to może znaczyć, że stała się ona celem właśnie takiego ataku. Jak łatwo się domyśleć, radzenie sobie z tego typu zagrożeniem stało się chlebem powszednim wszystkich usługodawców w Internecie.
Batalia o dostępność usług jest prowadzona wszelkimi metodami. Od manualnego i ordynarnego blokowania celu ataku (i ratowania postronnych ofiar), po zautomatyzowane, wysublimowane i wielostopniowe procesy filtrowania. Oczywiście czym wygodniejsze (mniej angażujące i ingerujące) rozwiązanie tym bardziej kosztowne, a specyfiką ataków DDoS jest przepaść między kosztem jego organizacji, a środkami jakie trzeba zaangażować, aby się ochronić.
Charakterystyka rozproszonej (“distributed”) sieci źródeł ataku dodatkowo powoduje, że w zasadzie tylko operatorzy telekomunikacyjni (dostawcy Internetu) są w stanie skutecznie organizować obronę. EXATEL w tych działaniach nie jest odosobniony i poszedł nawet o krok dalej.
Podejście EXATEL
Techniki ataków cały czas ewoluują, a w związku z tym konieczne jest aktualizowanie zabezpieczeń. EXATEL zdecydował się zbudować autorskie rozwiązanie TAMA jako odpowiedź na potrzebę bezpośredniego wpływu na rozwój systemu ochrony DDoS w zależności od realnych (a zarazem zróżnicowanych) wymagań klientów podlegających atakom.
Dzięki temu, że mamy możliwość ciągłej analizy charakterystyki ruchu w sieci, jeśli wykryjemy nietypowe zdarzenie (i zakwalifikujemy je jako szkodliwe) – możemy natychmiastowo reagować i sprawnie filtrować złośliwy ruch z sieci. Dzięki temu umożliwiamy normalne działanie atakowanego serwisu.

Czym jest TAMA?
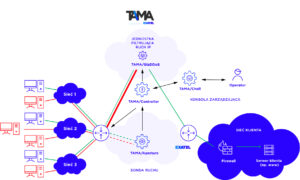
TAMA to skalowalne i wydajne rozwiązanie programistyczne chroniące sieć przed atakami typu DDoS (ang. Distributed Denial of Service). EXATEL zbudował rozwiązanie w modelu usługowym (ang. as a service). Ochrona przed wolumetrycznymi atakami DDoS jest oparta na platformie centralnej.
TAMA składa się z kilku elementów:
- Aperture monitoruje ruch sieciowy z routerów brzegowych agreguje informacje statystyczne i przekazuje do Kontrolera.
- Kontroler integruje informacje z sond w postaci “aktualnego stanu o monitorowanej sieci”, zapisuje je do bazy analitycznej, podejmuje decyzje o wykryciu, podtrzymaniu i zamknięciu alarmu, uruchamia i zatrzymuje automatyczne mitygacje.
- GlaDDoS to jednostka filtrująca. Jest skalowalny. Przepustowość na jednym GlaDDoSie zależy od ustawień polityki mitygacji oraz od parametrów serwera, na którym został uruchomiony. Dla osiągnięcia jak najlepszej wydajności, nasze jednostki filtrujące są rozproszone geograficznie.
- Chell to konsola zarządzająca, pozwala administratorom i operatorom dbać o bezpieczeństwo sieci naszych klientów.
- Portal klienta to dodatkowy element, za pośrednictwem którego nasi klienci mogą obserwować alarmy i mitygacje wyzwolone dla swoich obiektów oraz monitorować ruch w swojej sieci.
Na czym polega innowacyjność produktu?
- Architektura rozwiązania oparta o ogólnodostępny sprzęt w architekturze x86 – bez drogich układów FPGA i ASIC
- Osiągnięcie przepustowości rzędu 100 Gb/s – dzięki wykorzystaniu efektywnych technik skalowania (pionowego i poziomego)
- Autorskie mechanizmy i techniki zawierające elementy uczenia maszynowego
- Możliwość pracy w trybie multi-tenancy (równoczesna ochrona wielu klientów z różnymi politykami) oraz ochrony łącz niezależnie od działania dostawcy
- Opracowanie szybkiego i elastycznego silnika decyzyjnego do identyfikacji i neutralizacji zagrożeń

Czym jest TAMA PRO7?
TAMA PRO7 jest Kontynuacją projektu TAMA tj. zestaw dodatkowych modułów, w które zostanie wyposażone rozwiązanie TAMA anty-DDoS.
Dzięki TAMA PRO7 możliwe jest przeciwdziałanie:
- nowym atakom wolumetrycznych (dzięki dodaniu nowych technik w obszarze detekcji i mitygacji ataków DDoS)
- atakom na zasoby serwera usługi (w tym atakom na fragmentację)
- atakom na warstwę aplikacyjną
- atakom BGP hijacking
—–
 |
Projekt współfinansowany przez Narodowe Centrum Badań i Rozwoju w ramach programu CyberSecIdent „Cyberbezpieczeństwo i e-Tożsamość”. Wartość całkowita projektu wynosi 11 502 685,00 PLN, z czego wartość dofinansowania stanowi 8 116 987,00 PLN”.
Tytuł projektu: ARFA – rozwiązanie programistyczne chroniące wielokontekstowo przed zaawansowanymi atakami DDoS (Distributed Denial of Service).
Umowa o dofinansowanie numer: CYBERSECIDENT/487721/2021/IV/NCBR/2021.
Okres realizacji projektu: 01.06.2021 – 31.05.2023.
TAMAbox
Tytuł projektu: TAMAbox – wirtualne i fizyczne urządzenia chroniące przed atakami typu DDoS (Distributed Denial of Service).
Cel projektu: opracowanie prototypów i przygotowanie wdrożenia jako produktu rozwiązania technologicznego do ochrony sieci i aplikacji teleinformatycznych przed nowymi typami ataków DDoS.
Umowa o dofinansowanie nr: FENG.01.01-IP.01-0013/23-00
Wartość kosztów kwalifikowalnych projektu wynosi 19 695 000,00 PLN, z czego dofinansowanie stanowi 10 560 625,00 PLN.
Okres realizacji projektu: 01.10.2023 – 31.01.2026.
Projekt jest współfinansowany ze środków Unii Europejskiej w ramach programu „Fundusze Europejskie dla Nowoczesnej Gospodarki 2021-2027.
Planowane działania w projekcie:
- Badania nad nowymi algorytmami detekcji ataków, wraz z ich akceleracją w platformach sprzętowych do wykrywania na ukierunkowane oraz dotkliwe ataki DDoS
- Badania nad nową generacją adaptowalnych architektur systemów informatycznych wykorzystujących sztuczną inteligencję i algorytmy przetwarzania danych do ochrony sieci przed atakami DDoS
- Opracowanie nowych i ulepszonych wersji istniejących komponentów systemu TAMA
- Opracowanie prototypu wirtualnego rozwiązania TAMAbox
- Opracowanie prototypu platformy fizycznej TAMAbox
W projekcie będę ponoszone koszty związane z:
- Wynagrodzeniami kadry B+R projektu
- Pracami podwykonawczymi
- Kosztami pośrednimi
Głównymi odbiorcami usługi opartej na opracowywanym rozwiązaniu będą wszelkie organizacje i przedsiębiorstwa, które mają wystawione w Internecie takie zasoby jak:
– serwery WWW,
– serwery aplikacyjne,
– serwery bazodanowe,
– serwery mailowe,
– serwery DNS,
– serwery VoIP.

Jesteś zainteresowany tą tematyką?
Zajrzyj na Blog_
 Artykuł
Artykuł
Godfather | Nowe funkcje malware’a wykradającego dane bankowe
Firma Zimperium, specjalizująca się w bezpieczeństwie urządzeń mobilnych, opublikowała raport dotyczący nowych metod poz...
 Artykuł
Artykuł
Niewidzialne zagrożenia: bezpieczeństwo w cieniu „security blind spots...
W dzisiejszym, dynamicznym świecie cyfrowym, bezpieczeństwo stało się priorytetem dla firm i jednostek.
 Artykuł
Artykuł
Skanuj bezpiecznie! Czyli o kodach QR, ich wykorzystaniu i cyberbezpieczeństwie...
W obecnym świecie, w którym mobilność i wygoda są kluczowymi aspektami, kody QR (z ang. Quick Response) stały się nieodł...
Praca w projekcie TAMA EXATEL_
