
W projekcie TAMA, oprócz używania narzędzi do statycznej analizy kodu oraz testowania z użyciem sanitizers, jednym ze sposobów w jaki zwiększamy bezpieczeństwo jest fuzz testing. Fuzzing to technika testowania oprogramowania, która polega na wysyłaniu do programu różnych prawidłowych/nieprawidłowych/losowych danych i obserwowaniu zachowania programu.
W tym artykule opiszę w jaki sposób fuzzujemy nasz filtr pakietów z użyciem kompilatora clang i libFuzzer.
Kod do przetestowania
Działanie filtra pakietów
Nasz filtr pakietów – GlaDDoS – w uproszczeniu wykonuje taki algorytm (pseudokod):

W tym algorytmie można dostrzec dwa miejsca w których operujemy na danych, które mogą powodować błędy:
- decode-funkcja, która pobiera N bajtów i zwraca strukturę pakietu np. (proto=IPv4, src=1.2.3.4, dst=5.6.7.8);
- metoda process każdego filtra, która operuje już na zdekodowanym pakiecie. Logika tych metod jest zależna od binarnych danych które otrzymaliśmy.
Kod C++
A tak wygląda kod w C++.

Klasa bazowa Filter otrzymuje w metodzie process pakiet i zwraca informację, czy pakiet powinien być przesłany dalej lub odrzucony. Podklasy implementujące jej interfejs to np.:
- InvalidPacketFilter – odrzuca pakiety błędne (niepoprawna suma kontrolna, błędy w nagłówkach) i nielogiczne (pakiety TCP z flagami SYN i RST itp.);
- GEOFilter – odrzuca pakiety, które pochodzą z krajów znajdujących się na czarnej liście.
Następnie, klasa Pipeline posiada listę filtrów i konfigurację filtrowania dla chronionych przez nas adresów. Konfiguracja zawiera np. informację, które filtry są dla danego adresu włączone lub które kraje są na białej/czarnej liście.

Fuzzing z użyciem libFuzzer
Kompilator clang pozwala bardzo łatwo rozpocząć fuzzing. W nowym pliku źródłowym należy jedynie zdefiniować funkcję, którą wywoła fuzzer. Powinna przyjmować dwa argumenty -wskaźnik na dane i rozmiar:

Przed rozpoczęciem testowania, czasem trzeba będzie zrobić jakąś globalną inicjalizację. Inicjalizację można zrobić przez definicję funkcji, która będzie wywołana przez libFuzzer tylko raz przy starcie programu.
W naszym przypadku musimy zainicjalizować Pipeline, ponieważ domyślnie wszystkie filtry są wyłączone, więc żaden nie będzie testowany – tutaj, konfigurujemy Pipeline tak, by każdy możliwy adres IPv4 miał włączone wszystkie filtry.
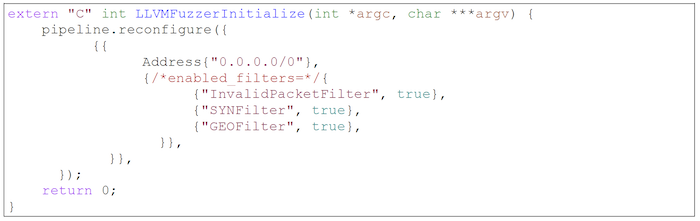
Kompilacja i uruchomienie:
![]()
Po uruchomieniu fuzzer będzie działać w nieskończoność lub dopóki program nie wykona błędnej operacji, którą wykryje AddressSanitizer lub UBSan.
Użycie z CMake
W naszym projekcie używamy CMake do konfiguracji systemu budowania. Aby łatwo budować fuzzer, w katalogu w którym znajduje się jego plik źródłowy mamy plik CMakeLists.txt:

Oraz, w głównym CMakeLists.txt dla projektu mamy opcję włączenia budowania z fuzzerem:

Dzięki temu, przy budowaniu projektu można łatwo zbudować również fuzzer:

Custom mutator
Gdy rozpoczęliśmy fuzzing, początkowo byliśmy zdziwieni, że fuzzer nie znajduje żadnych błędów – nawet tych oczywistych, przygotowanych dla testów. Po analizie i sprawdzeniu pokrycia kodu przez fuzzer odkryliśmy, że tylko pierwszy filtr był testowany.
Działo się to dlatego, że pierwszy filtr – InvalidPacketFilter – sprawdza sumę kontrolną IPv4 w pakiecie i odrzuca każdy pakiet dla którego się ona nie zgadza. Oczywiście fuzzer nie wie jak wygenerować pakiety z poprawną sumą kontrolną. Z tego powodu fuzzer utknął na pierwszym filtrze i nie zwiększał swojego pokrycia.
Aby rozwiązać ten problem, użyliśmy własny „mutator” danych wejściowych. Mutator to funkcja, która w jakiś sposób zmienia wygenerowane dane wejściowe, by pokryć większą część kodu.
W naszym przypadku, przed każdym LLVMFuzzerTestOneInput najpierw robimy standardową mutację danych, a potem obliczamy sumę kontrolną i nadpisujemy ją w nagłówku IPv4.


Seed corpus
Fuzzer można uruchomić z własnymi danymi wejściowymi. Nie jest to konieczne, bo libFuzzer sam potrafi wygenerować dane, które powodują poszerzenie pokrycia. Niemniej jednak dzięki temu, szybko można je poszerzyć.
Katalog, który zawiera pliki z danymi wejściowymi nazywa się „corpus”. W naszym przypadku w każdym pliku będzie znajdować się pakiet binarny. Dla GlaDDoSa wygenerowaliśmy te pakiety przy użyciu narzędzia scapy.
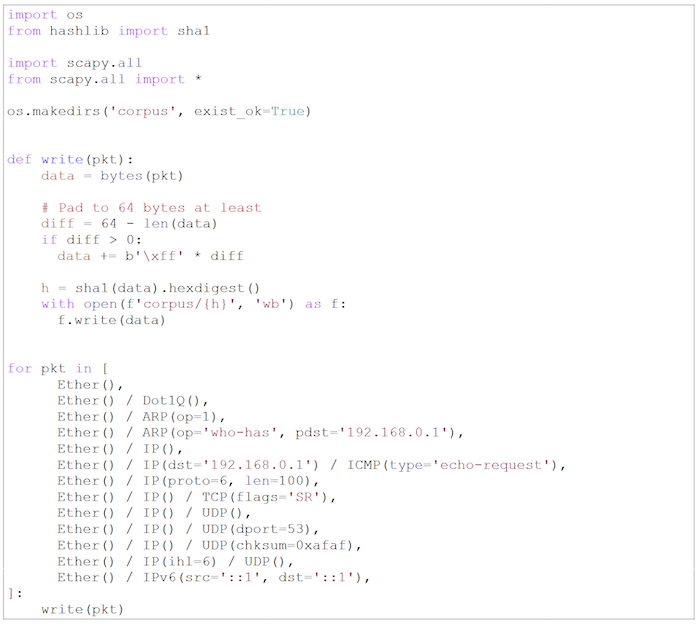
Po uruchomieniu takiego skryptu, możemy wywołać fuzzer na wygenerowanym corpusie:
![]()
Debugging
Gdy podczas działania fuzzera w programie wystąpi fatalny błąd, to fuzzer zakończy swoją pracę i zapisze dane, które wygenerował i powodują błąd oraz pokaże nazwę pliku:
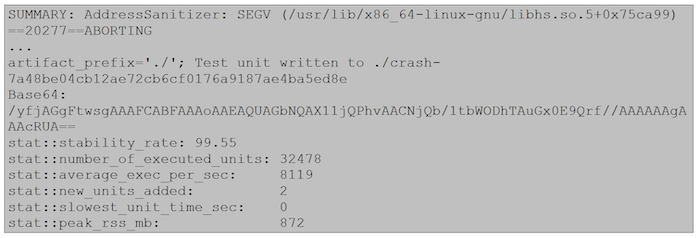
Mając takie dane, możemy przeanalizować pakiet z użyciem narzędzia scapy oraz znaleźć przyczynę błędu:
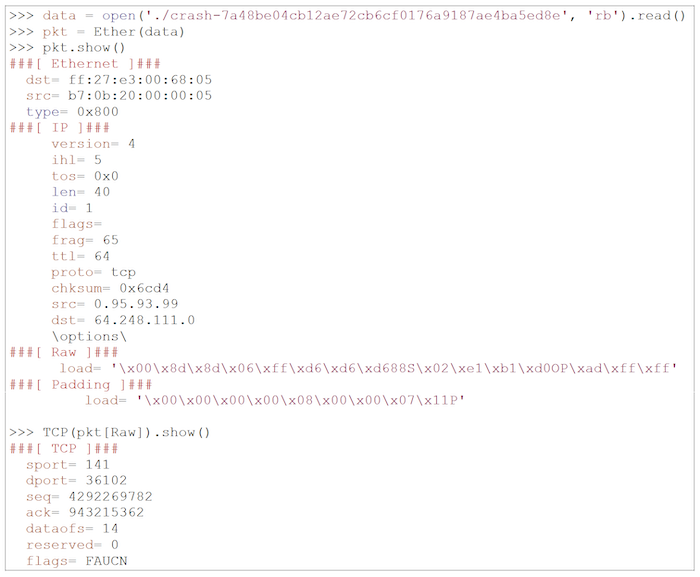

W tym przykładzie, TCP data offset jest za duży. Przez to nasz program próbuje czytać dane poza zakresem i otrzymuje fatalny sygnał SIGSEGV.
Podsumowanie
Fuzzing jest bardzo przydatną techniką znajdowania błędów w programach. W projekcie TAMA używamy dedykowanego serwera do fuzzingu.
Do tej pory fuzzer wygenerował około 3 biliony pakietów i znalazł już kilkanaście krytycznych błędów, które mogłyby znacząco narazić naszą infrastrukturę oraz klientów na realne straty. Zastosowanie go jako składowej w procesie wytwórczym nie tylko ułatwia nam wykrycie błędów -także uszczelnia sam proces. Dzięki identyfikowaniu błędów -zarówno tych krytycznych, jak i tych mniej znaczących -wyciągnęliśmy wnioski i nauczyliśmy się jak pisać lepszy, bezpieczniejszy kod.
Fuzz testing na pewno sprawdził się u nas i będziemy kontynuować stosowanie tej techniki i usprawnianie procesu fuzzingu.


