

Do skutecznego przeciwdziałania atakom DDoS potrzebne są trzy elementy:
- specjalizowane/dedykowane platformy sprzętowe/mechanizmy sieciowe,
- wykwalifikowani inżynierowie odpowiedzialni za konfigurację narzędzi oraz monitorowanie zdarzeń sieciowych,
- ustalone procesy i procedury obsługi incydentów.
Im „dalej” od użytkownika końcowego zostanie rozpoczęta mitygacja ataku DDoS, tym mniejszy wpływ na daną infrastrukturę będą miały działania prowadzone przez atakujących. Oczywiście zapewnienie odpowiedniego poziomu ochrony powinno mieć strukturę warstwową. W ramach tego artykułu zostaną przedstawione wybrane mechanizmy stosowane przez operatorów telekomunikacyjnych świadczących usługi dostępu do sieci Internet. Zanim atak dotrze do „wąskiego gardła” jakim jest łącze dostępowe, może zostać poddany procesowi mitygacji już w sieci dostawcy usług.
Identyfikowanie zdarzeń sieciowych i wektorów ataku
Przed rozpoczęciem czynności mających na celu udaremnienie działań atakujących, należy najpierw zidentyfikować te zdarzenia sieciowe oraz określić wektor przeprowadzanego ataku. Analiza ruchu IP może być prowadzona na kopii ruchu (tzw. mirroring), zbierając dane z liczników urządzeń sieciowych (np. SNMP) lub z wykorzystaniem dedykowanych protokołów przekazujących informacje o przetwarzanym ruchu (np. Netflow, sFlow, IPFIX). Ze względu na mało skalowalne metody oparte na kopiowaniu ruchu oraz ograniczenia detekcji opartych na ogólnych informacjach dostarczanych przez SNMP, największą popularność zdobyły usługi oparte na protokołach typu Flow/NetFlow. Na protokole, który zapoczątkował rodzinę tego typu rozwiązań, opracowanym przez firmę Cisco – Netflow, skupimy się w dalszej części artykułu. Protokół ten pobiera próbkę rzeczywistego ruchu, przepływającego przez routery PE (Provider Edge). Nagłówek próbkowanego ruchu jest umieszczany w rekordzie przepływu, który jest następnie eksportowany do komponentów systemu odpowiedzialnego za monitorowanie stanu sieci. Starsza wersja (v5) protokołu Netflow nie obsługuje IPv6. Nie pozwala ona również na uzyskiwanie statystyk i analizowania ruchu sieciowego w infrastrukturze działającej w oparciu o technologię MPLS. W związku z tym w sieci operatora najlepiej skupić się na wykorzystaniu Netflow v9.
Szerokie zastosowanie i duży potencjał Netflow v9 wynika z dynamicznego charakteru tego protokołu. Wcześniejsze wersje były statyczne, co oznacza, że dane eksportowane były w ściśle określonym formacie. Każde pole w eksportowanym strumieniu miało określone znacznie, a próba dołożenia nowej informacji wiązała się opracowaniem nowej wersji protokołu. W Netflow v9 zostały wprowadzone tak zwane szablony (tamplate-y) opisujące rodzaj danych w strukturze. Dokładny opis formatu ramki dostępny jest w materiale „NetFlow Version 9 Flow-Record Format„. Wyzwaniem jakie pojawia się wraz z taką elastycznością, jest prawidłowa konfiguracja kolektora danych przepływów. Istnieje realne ryzyko, że kolektor nie będzie w stanie prawidłowo zinterpretować informacji otrzymanych w rekordach wygenerowanych na podstawie nowych szablonów i w związku z tym odrzuci bądź błędnie przetworzy takie rekordy.
Prawidłowo skonfigurowany Netflow v9 pozwoli jednak na skuteczne monitorowanie zdarzeń w sieci transmisyjnej. Jest z powodzeniem stosowany zarówno przez krajowych jak i międzynarodowych oparatów – głównie dzięki niskim kosztom implementacji, dużej elastyczności oraz skalowalności.
Poznaj wroga czyli analiza ruchu
Ze względu na charakter ataków DDoS bardziej istotna jest analiza ruchu skierowanego do zasobów objętych ochroną (adresu lub adresów IP). Ruch ten powinien podlegać zliczaniu minimum z wykorzystaniem 2 wartości:
- liczby megabitów na sekundę wysyłanych do danego obiektu (Mbps),
- liczby pakietów na sekundę wysyłanych do danego obiektu (pps).
Określenie oczekiwanych wartości parametrów ruchu, powinno odbywać się na podstawie analizy realizowanej w okresie prawidłowego działania sieci. Charakterystyki ruchu prawidłowego wynikają bezpośrednio z usług/działań realizowanych na konkretnych chronionych zasobach. Rozpatrując powyższe oraz dodatkowe parametry w zgromadzonych danych, tworzy się reguły/mechanizmy detekcji, śledzące wszelkie odstępstwa od wcześniej zidentyfikowanych wartości bądź zdefiniowanych progów statycznych. Jako bardzo prosty przykład można przyjąć, że dla serwera webowego naturalnym stanem będzie transmisja danych wykorzystująca protokół TCP. Zatem wystąpienie ruchu sieciowego w protokole UDP można uznać za anomalię lub/i powinien być poddany dalszej analizie pod kątem sytuacji podejrzanej. Innym przykładem może być monitorowanie średniej liczby nawiązywanych/zamykanych sesji TCP (3-way-handshake) w jednostce czasu. Nagły, znaczny wzrost jednego z tych parametrów powinien wyzwolić alarm. Im lepsza znajomość chronionej sieci, w tym, wiedza o uruchomionych usługach na konkretnych adresach IP, tym skuteczniejsze polityki detekcji można opracować.
Parametry, które warto monitorować:
- źródłowe oraz docelowe adresy IP,
- źródłowe oraz docelowe porty,
- protokoły warstwy transportowej (TCP, UDP),
- data, godzina,
- źródłowy oraz docelowy ASN,
- rozmiar pakietów,
- flagi w nagłówkach,
- fragmentacja.
Przykładowe dane zebrane przez system, mogące posłużyć do analizy zdarzenia sieciowego:
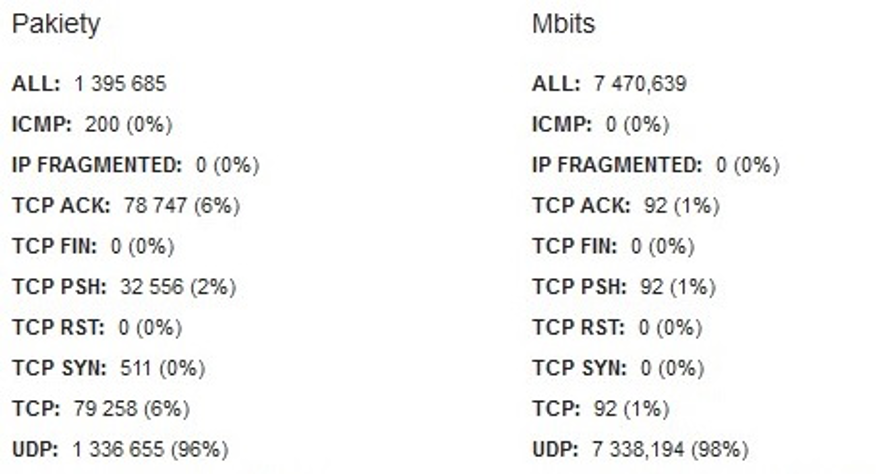
Rys. 1. Dane liczbowe pps oraz Mbps
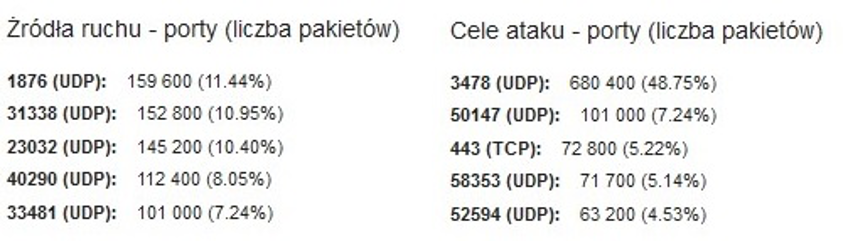
Rys. 2. Zarejestrowane porty i protokoły komunikacyjne
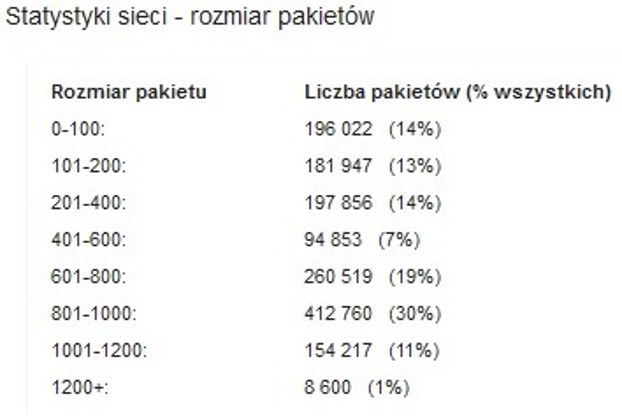
Rys. 3a. Statystyki rozmiaru pakietów
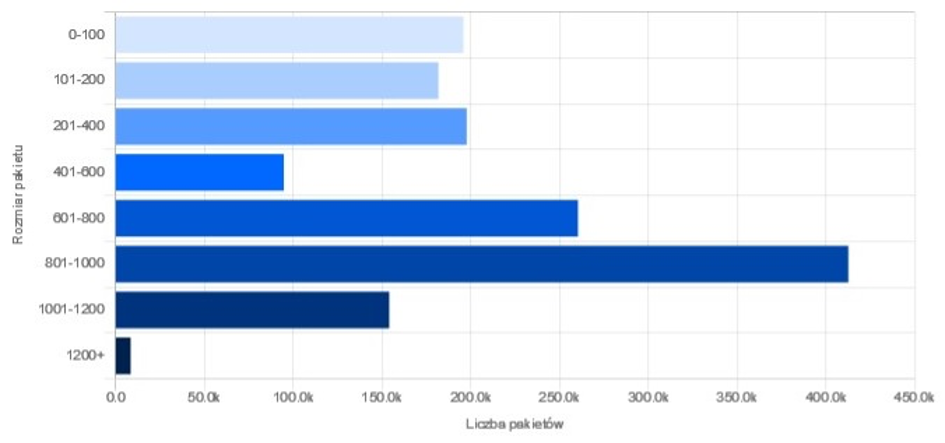
Rys. 3b. Statystyki rozmiaru pakietów – wykres
Podsumowanie
Połączenie zaprezentowanych, przykładowych informacji pozwala określić typ i charakter zdarzeń występujących w sieci. Na tej podstawie możliwe jest podejmowanie dalszych kroków mających na celu radzenie sobie z występującymi incydentami. Wszelkie informacje zebrane na etapie detekcji, poza wyzwoleniem dedykowanego alarmu i określeniem jego poziomu w systemie monitoringu, mogą wskazywać konkretną metodę obsługi incydentu/mitygacji ruchu. Operatorzy stosują różne metody obsługi/filtrowania ataku wynikające zarówno z poziomu wykupionej usługi jak i z realnej możliwości obsługi ataku o konkretnej sygnaturze.
Mechanizmy mitygacji zostały szerzej opisane w drugiej części artykułu.


