
Ars numerandi
Since the early days of computer science we had been trying to optimize code and get the most out of available hardware. At the time, it was largely due to necessity – expectations for displayed graphics, whether in games or, for example, in simulations, initially always exceeded the capabilities of the available hardware. The memory of those dark times is slowly fading, stories become more and more hazy… but back in the day displaying a character, moving backgrounds, and synchronizing 8-bit music required writing a powerful assembler code, and in-depth knowledge of architecture (Commodore? Atari? ZX Spectrum?) that the code was written for, and often creative use of CPU mechanisms intended for something completely different.
The nostalgia for those times can be seen in some of the concepts of the demoscene – a somewhat hard to grasp subculture centred around computer-generated art – sometimes with truly absurd assumptions. Because when you think about it, doesn’t the concept of generating a 3 minute 3D movie, with music, using a program that takes up 4096 characters (4x less than this article) just seem absurd? Especially when we read about it using a browser taking up over 200MB of disk space and 8GB (oh, 9 already) of RAM?
Today’s IT has a problem with being “overweight ”, but for a good reason. Multiple layers of abstraction reduce performance but allow us to create and implement solutions faster. This speed is usually imposed on us by the industry, which would rather have a working solution today than an optimum one in a month (or never). And it is hard to argue, it usually makes sense.
Sometimes, however, there is a need for a programmer to demonstrate knowledge of what lies beneath all those convenient layers of abstraction with which they work every day. This need is precisely one of the reasons why I was so pleased to be involved in the creation of “TAMA” ( – the system protecting against DDoS attacks. It is the opportunity to return to a slightly more “primal” computer science.
Protection against DDoS attacks
Our goal was not to generate graphics. We had to detect and mitigate attacks that involve denying service to a client – essentially by “saturating the resources” of the server providing it. Usually, the saturated resource is the network, but it can also be the server memory or CPU.
Detection was based on observing “metadata” about network traffic – described using the Netflow protocol. This data is aggregated and averaged, so we can detect its anomalies, such as exceeding a packet-per-second threshold configured for the server. It is described as “meta” because netflow is network traffic that describes approximately other network traffic. It does not contain the packet content itself and only describes one transmitted packet out of, for example, a thousand.
Simultaneous tracking of traffic up to tens of thousands of addresses, processing and storing traffic information in databases may not be trivial, but it is also not very demanding in terms of performance and can be easily scaled to multiple cores. In the end, it turned out that we only need one physical machine. Packet parsing and pre-aggregation using C++ and most of the detection and database handling written in Python. For this reason, detection is not the topic of this article.
Also, not all attack mitigation methods need to be difficult to implement. One method used is to cut off routing to the attacked IP address – the so called “BGP Blackholing”. The system detects an attack, which usually comes from many distributed addresses, to a specific target IP address and… cuts off traffic to it completely. This saves the other servers and services using the same connection. In case of a massive (several dozens of gigabytes per second) attacks that overload the operator’s infrastructure, this may be the only real way to limit the impact of the attack.
However, this method is quite primitive and by limiting the attack in this way, we fulfil the attacker’s wish – the service is not available to the clients.
In the remaining part of this article, I will focus on the challenges of implementing a more elaborate method of mitigation: redirecting traffic – both the traffic of customers who want to use the service and the attack that tries to prevent them from doing so – to units that actively filter network packets.
Packet filter
We did not put artificial limitations, the filter did not have to fit in 4096B, but we had enough things to worry about:
- Traffic filtering had to be economical – $/Gbit/s.
- We wanted the solution to be easily extensible – attacks change, and so we should too. Implementing a change in the devops/agile spirit should be achievable in 1-2 weeks (from concept to implementation).
- We wanted to filter traffic as close to its source as possible – at the edge of our network, at multiple geographically dispersed points.
Today, a company backbone links are very often 10GbE fibre optic ones, occasionally 40GbE and increasingly also 100GbE. Therefore, we wanted a single filter server to be able to handle 10-40GbE of traffic, as we planned to run several machines to ensure high system availability.
However, bandwidth is not everything. 40GbE could be almost 60 million packets per second (Mpps) if we are attacked with small, 64-byte packets, or less than 4Mpps if the frame size reaches 1500B. The Mpps measure turns out to be much more important than the link bandwidth. We need to spend a fixed amount of time on each frame, analysing the header and verifying the response of the filtering mechanisms. Sometimes, to make a decision, the entire packet will need to be reviewed (e.g. to check regular expression rules).
Finally, based on the analysis of attacks occurring, we decided that one physical filter should handle at least 10Mpps of traffic. As it later turned out, it was not that much at all.
We write software!
This mix of requirements made us decide to implement the filter purely in software, ensuring that it would work on widely available computers and “off-the-shelf” network cards, the so-called COTS. Without using, i.a:
- Dedicated ASICs to accelerate specific operations,
- Reprogrammable circuits (FPGAs) integrated into network interface cards.
Instead, we used fairly powerful machines and “slightly better” network interface cards, such as the quite popular Intel X710, which allowed us to connect to the server four links with the throughput of 10GbE each.
Most of the boring work of handling network traffic, in a normal operating system, will be done by its kernel (using Linux as an example):
- The network card will pick up a packet, or even several packets – just not to bother the system too often (so called “coalesce” – one of many optimizations).
- The interrupt will cause the kernel to copy the packet data to a structure in memory (skbuff) and start analyzing the different protocol layers (ethernet, IP, TCP).
- It will handle firewall rules (iptables, nft) for the packet depending on its destination.
- It will accept the packet (it is for us!) and pass the data to the application via a syscall (select, recv), or based on the routing table it will forward it to another network interface to the recipient or another router.
All these steps mean that your browser must be able to handle JavaScript, but it does not need to know much about the TCP – the system does most of the work, using a programming interface called “Berkeley Sockets”. It is probably the oldest (1983), still widely used and recognized API: socket, bind, listen, accept, recv, send, connect.
Unfortunately, if you try to push 10 Mpps through this full system stack – you may end up disappointed. Interrupts, memory copying, RFC-compliant packet parsing, syscalls crossing the user-kernel space boundary make it impossible for a modern computer system to keep up. It quickly became clear that meeting the performance requirements needs a dedicated solution that also requires more effort.
We chose the DPDK library to create the filter. It gave us mechanisms to bypass the operating system when receiving and transmitting packets and talk directly to the network card through a shared RAM – without unnecessary and expensive data copying. Instead, we had to write ourselves all the necessary elements of the TCP/IP protocol stack (Ethernet, VLAN, IPv4, IPv6, TCP, UDP, ARP, ICMP PING, GRE).
Linux also has other APIs, newer and more powerful ones than Berkeley Sockets (e.g. PF_RING) but they do not solve our problem more comprehensively than the DPDK.
Computers are so fast these days!
We will process packets faster, but it will not solve all our problems. As an experiment, we measured the following: it takes us between 4000 and 11000 CPU cycles to read a packet and run the filtering mechanisms, depending on the configuration of the mitigation method. How many cycles do we have at our disposal?
| size | transmitted bits | tx time @40GbE | max PPS | CPU ops/packet |
| 64B | 672 | 0.0168ms | ~ 59mln | ~ 520 |
| 512B | 4256 | 0.1064ms | ~ 9.3mln | ~ 3300 |
| 1500B | 12160 | 0.304ms | ~ 3.2mln | ~ 9400 |
(The transmitted bits take into account the inter-frame-gap and the preamble.)
On a 40GbE link, a new 64B packet can occur every 520 CPU instructions or so, and a 1500B packet – every 9400. That is less than the 11,000 we need! Are CPUs too slow?
The speed at which the CPU core can process data has not increased enough to keep up with the growth of our information and throughput. Speed gains have slowed down in recent years – we have reached the 5-14nm lithography process and are approaching the hard physical limits of the silicon. Fortunately, we have also learned to increase the number of CPU cores – so not all is lost. To achieve the goal, we are forced to write a parallel program that will simultaneously execute on multiple cores.
However, putting all the blame on the CPU would be a gross oversimplification. For many years, the access speed of RAM has grown slower than the speed of CPUs, the available number of CPU cores and available memory size. This phenomenon is called the “memory gap” or the “memory wall”. The widely used DDR4 standard dates back to 2014 (DDR5 was announced in July 2020).
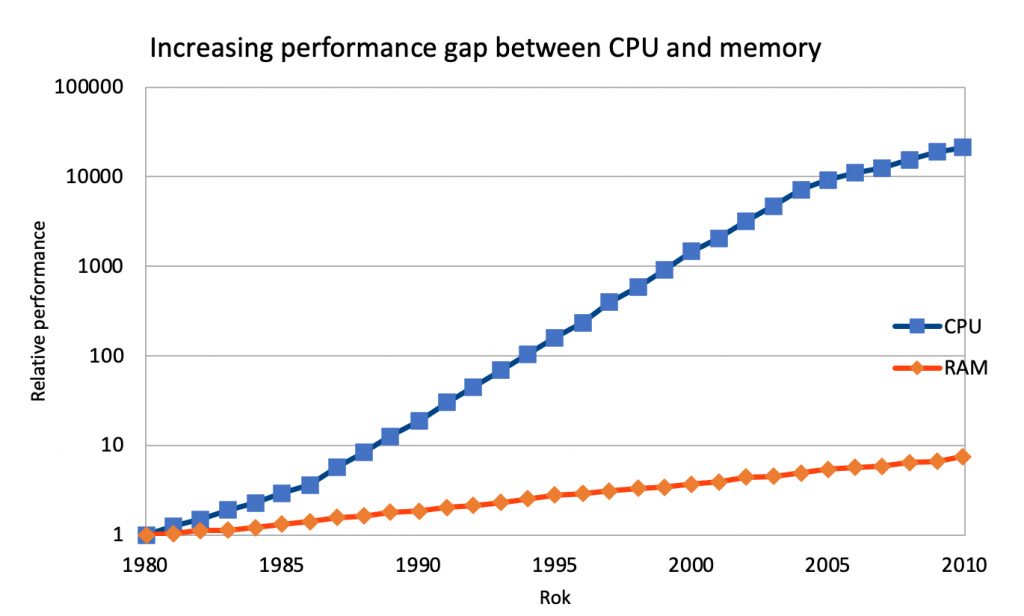
In practice, very often the CPU would like to work but it cannot do so because it is waiting for the lagging RAM. There is a number of measures that can minimize this effect:
- Cache memory – each core and CPU have a small bit of cache memory that is physically located closer and is faster (but also more expensive) than RAM. Its effective use is the key to performance.
- Optimizing compilers can change the order of program operations so that fetching data from memory occurs long before the information is actually needed for the computation – so that memory has time to deliver it to the cache.
- Deep pipelining in CPUs – when one instruction is executed by the core, another one is fetched, and one more is decoded to work with optimum performance with slower memory.
- Instructions can even be executed in advance – by the time we get the data for the previous instruction, we are already working on the next one. With execution branching (“if” condition in code), the CPU will guess which way to go. In case of branch misprediction, it may so happen that we have done some unnecessary work (10-20 instructions) that should be discarded, and we have to start again. Flaws in these mechanisms were the cause of the Meltdown and Spectre attacks.
- Hyperthreading – when one pipeline is waiting for data, another one can execute instructions – allowing one actual CPU core to do the work of two.
- NUMA architectures – if multiple CPUs share memory, the memory gap widens. You can divide the memory into the CPUs so that each one has “its own” memory, in addition to accessing “foreign” memory, which is slightly slower but possible. Good optimization of memory usage on such an architecture can significantly improve performance but programming the same is more difficult.
The subject matter is so complex that if, in the past, the software developer optimizing a program had a chance to understand in detail the architecture for which they were writing a code (Z80, 6502, …), it is virtually impossible to do so nowadays. We rely much more on empirical measurement of code snippet performance and experimental fixes than we used to in the past.
The hardware goes to great lengths to pretend that nothing weird is going on underneath, and meanwhile the computer works just like it did in the 1980s. For example, many CPU cores, each with its own cache, can write and read – at the same time – the same part of the memory.. Despite this, an x86 or x86_64 CPU provides cache coherence in a way that is invisible to the programmer – after a write is performed, all cores read the new stored value, not the old one, from the caches.
Memory behaviour has been defined for the C++ programmer fairly recently – with the C++11 standard. There, a memory model and tools were created to make efficient use of hardware properties. For example, a set of atomic operations on variables (e.g., test-and-set, compare-and-swap) was introduced that language library developers would use to build more complex synchronization mechanisms like semaphores and mutexes.
These mechanisms make writing parallel programs possible – but not necessarily easy. The CPU can pretend that everything is as it was, no pipelining, no memory access issues, etc. If the programmer does not understand how everything they do works “under the hood”, such code may work – but it will run slower.
How to write a code to achieve high throughput?
So what have we done to ensure that our program, operating within the available mechanisms, achieves the 10Mpps target?
- We run multiple threads, pinned to different CPU cores, so that each core handles some network traffic in parallel.
- Using the hardware mechanisms of the network card, with the help of DPDK library, we divide the network traffic among the active cores in such a way that one TCP or UDP connection sticks to the same core, e.g., using a hash function on IP addresses: hash(src ip + dst ip) % number_of_cores. Here we cheat a bit by using the hardware help, but it is a fairy popular and available feature.
- We wrote each of the threads so that it never got in the way of the others – it did not wait for them, nor did they wait for it. This means that we cannot use popular, high-level, lock/mutex mechanisms for data synchronization. Otherwise, we will not get a linear increase in performance as the number of threads increases (see https://en.wikipedia.org/wiki/Amdahl%27s_law)
- Since we cannot synchronize threads… then we cannot dynamically allocate memory, and this limits the choice of data structures we use – for example, you cannot use std::set to store information about whether we have already seen a given address.
- Each thread will have read-only access to a portion of memory with system configuration, IP address lists, etc. Shared data will use L3 cache efficiently
- Each thread also gets a bit of its own writable memory – for event aggregation, statistics, filter state. We statically allocate memory before running the filtering loop.
- We optimized RAM access and avoided branching while writting the code running a single thread.
- Parallel threads need to be coordinated: main thread prepares the mitigation configuration, collects job statistics, and coordinates with the rest of the TAMA system.
Eventually, using the DPDK, C++17, lock-less data structures and e.g. a 12 core CPU with clock speed 3Ghz with a full set of software filters enabled (including a Regexp filter – https://www.hyperscan.io) we are able to handle 25 Mpps on a single physical machine. By applying several machines of this type in a network and coordinating their work through a centralized REDIS database, we can provide a service of mitigating attacks, beyond simply cutting off the attacked computers from the Internet.
The description of the whole project context and introduction to efficient packet processing turned out to be so long that the topic of lock-less algorithms must be covered in the next article.


