
In the TAMA project, in addition to using static code analysis tools and performing tests with the use of sanitizers, fuzz testing is one of the ways to increase security. Fuzzing is a software testing technique that involves sending various valid/invalid/random data to a program and observing its behaviour.
In this article, I will describe how we fuzz our packet filter using the clang compiler and libFuzzer.
Code to test
Packet filter operation
Our packet filter – GlaDDoS – basically performs the following algorithm (pseudocode):

In this algorithm, you can see two instances where we operate on data that can cause errors:
- decode – function which takes N bytes and returns the packet structure e.g. (proto=IPv4, src=1.2.3.4, dst=5.6.7.8);
- process method of each filter, which operates on the already decoded packet. The logic of these methods depends on the binary data we received.
C++ code
And this is what the code looks like in C++.

The Filter base class receives the packet in the process method and gives feedback whether the packet should be forwarded or discarded. Subclasses implementing its interface include:
- InvalidPacketFilter – discards packets that are invalid (invalid checksum, header errors) and illogical (TCP packets with SYN and RST flags etc.),
- GEOFilter – discards packets that originate from blacklisted countries.
Next, the Pipeline class has a filter list and filtering configuration for the addresses we are protecting. The configuration includes, for example, the information which filters are enabled for a given address or which countries are whitelisted/blacklisted.

Fuzzing with libFuzzer
The clang compiler makes it very easy to start fuzzing. In the new source file, you only need to define the function that is called by the fuzzer. It should take two arguments – a pointer to the data and a size:

Before testing, sometimes it is necessary to do some global initialization.
Initialization can be done by defining a function that will be called by libFuzzer only once at program startup.
In our case, we need to initialize the Pipeline because all filters are disabled by default, so none of them will be tested – here, we configure the Pipeline so that every possible IPv4 address has all its filters enabled.
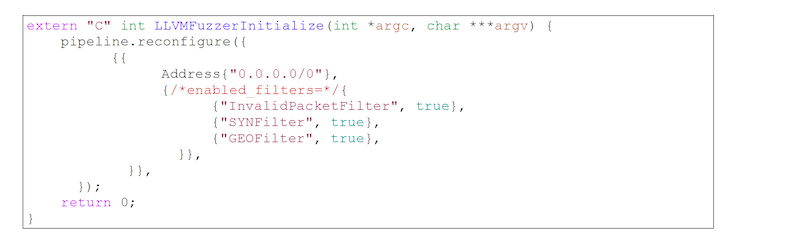
Compile and run:

Once started, the fuzzer will run indefinitely or until the program performs an erroneous operation that is detected by AddressSanitizer or UBSan.
Use with CMake
In our project, we use CMake to configure the build system. In order to easily build the fuzzer, we have a CMakeLists.txt file in the directory where its source file is located:

And, in the main CMakeLists.txt for the project we have an option to enable building with fuzzer:

Thanks to this solution, while building a project we can also build a fuzzer:

Custom mutator
When we started fuzzing, we were initially surprised that the fuzzer did not find any bugs – even the obvious ones prepared for testing. After analyzing and checking the code coverage made by the fuzzer, we discovered that only the first filter was tested.
This happened because the first filter – InvalidPacketFilter – was checking the IPv4 checksum in the packet and it discarded any packet without matches. Obviously the fuzzer did not know how to generate packets with the correct checksum. Because of this, the fuzzer stuck on the first filter and was not increasing its coverage.
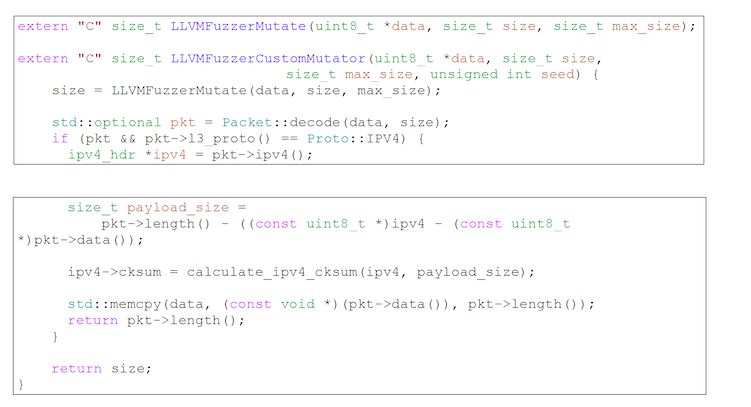
To solve this problem, we used our own input “mutator”. The mutator is a function that somehow changes the generated input to cover more of the code.
In our case, before each LLVMFuzzerTestOneInput, we first do a standard data mutation, and then we calculate the checksum and overwrite it in the IPv4 header.
Seed corpus
You can run the fuzzer with your own input. This is not necessary because libFuzzer itself can generate data that causes the coverage to expand. Nonetheless, it can be expanded quickly.
The directory that contains the input files is called the “corpus”. In our case, each file will contain a binary packet. For GlaDDoS, we generated these packets using the scapy tool.
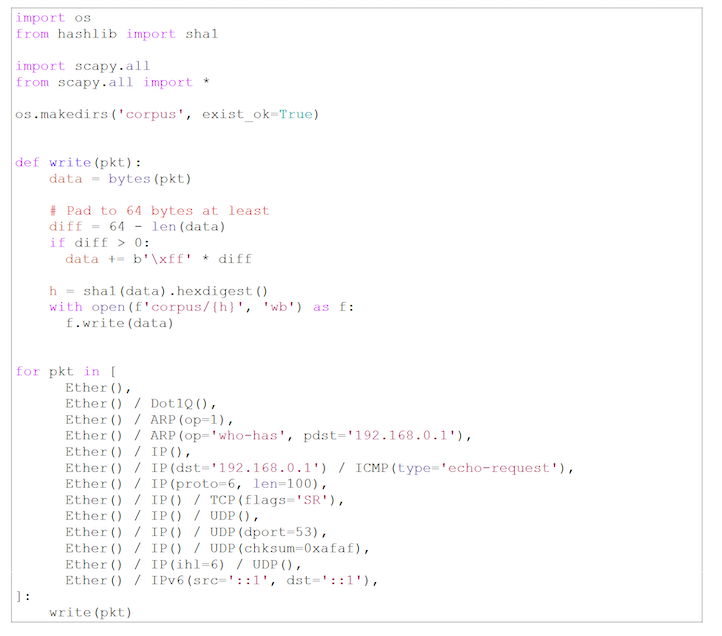
After running such a script, we can call the fuzzer on the generated corpus:
![]()
Debugging
When a fatal error occurs in the program while the fuzzer is running, the fuzzer will stop its operation and save the data it generated that causes the error and show the name of the relevant file:
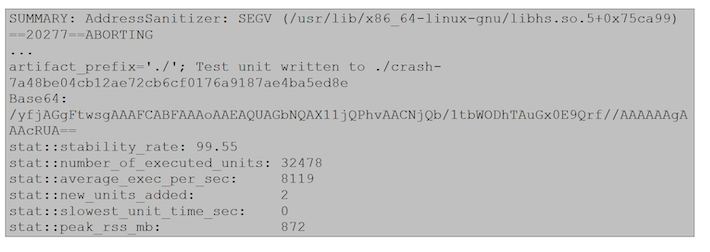
With this data, we can analyze the packet using the scapy tool and find the cause of the error:
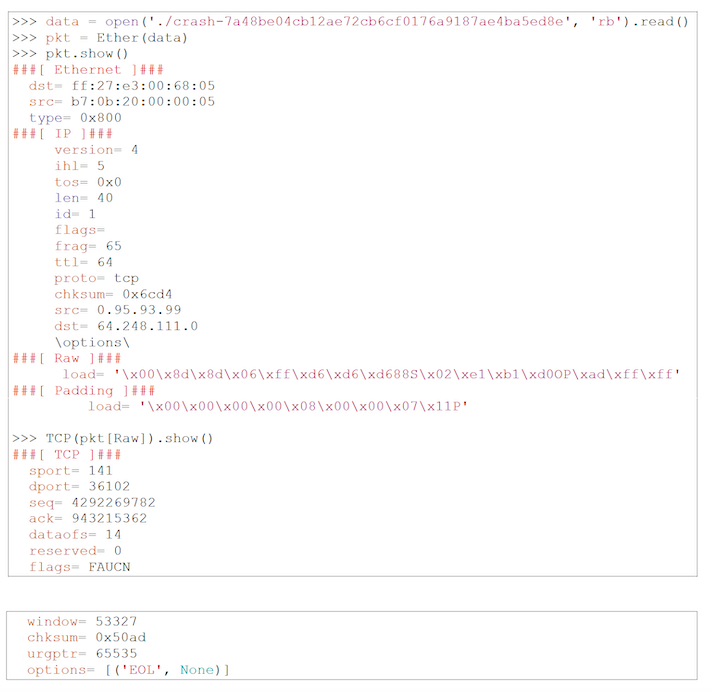
In this example, the TCP data offset is too large. Because of this, our program tries to read data out of range and gets the fatal SIGSEGV.
Summary
Fuzzing is a very useful technique for finding bugs in programs. In the TAMA project, we use a dedicated server for fuzzing.
To date, the fuzzer has generated about 3 trillion packets and has already found more than a dozen critical bugs that could significantly expose our infrastructure and customers to real losses. Its use as a component in the development process not only makes it easier for us to detect errors, but it also seals the process itself. By identifying bugs – both critical and less significant ones – we drew conclusions and learnt how to write a better, safer code.
Fuzz testing has certainly worked well for us and we will continue to use this technique and improve the fuzzing process.

